import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
Notes#
Lecture notes for BB1000 (20034) vt25
Basics#
Numeric data types#
8 * 9 # expression: values and operators
72
8
8
type(8 * 9)
int
type(8 / 9)
float
8 / 9
0.8888888888888888
8 // 9 # floor division
0
11 // 9
1
11 % 9 # modules , remainder
2
Complex number
x: real part y: imaginary part
type(1j)
complex
1j * 1j
(-1+0j)
1j ** 2
(-1+0j)
True
True
False
False
type(True)
bool
True or False
True
True and False
False
123 % 2 == 0 # True for even numbers
False
124 % 2 == 0 # True for even numbers
True
1 + 2 == 3
True
0.1 + 0.2 == 0.3
False
0.1 + 0.2
0.30000000000000004
Strings#
'Hello world'
'Hello world'
type('Hello world')
str
"Hello world"
'Hello world'
'Hello' == "Hello"
True
'It's time to go'
Cell In[27], line 1
'It's time to go'
^
SyntaxError: unterminated string literal (detected at line 1)
'It\'s time to go' # here \' means the literal apostrophe
"It's time to go"
"It's time to go"
"It's time to go"
"It's time\nto go" # \n refers to newline character
"It's time\nto go"
print("It's time\nto go")
It's time
to go
"It's time
to go"
Cell In[32], line 1
"It's time
^
SyntaxError: unterminated string literal (detected at line 1)
"""It's time
to go"""
"It's time\nto go"
# string operators
"Hello" + " world"
'Hello world'
"Hello" * " world"
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[35], line 1
----> 1 "Hello" * " world"
TypeError: can't multiply sequence by non-int of type 'str'
"Hello" * 3
'HelloHelloHello'
print("Hello world" + "\n" + len("Hello world")*'_')
Hello world
___________
# datatypes are also functions that convert values from one type to another
type(int('77'))
int
# ask year of birth and report age
print("What year were you born?")
year_of_birth = input()
print(year_of_birth)
age = 2025 - int(year_of_birth)
print("This year you will be " + str(age) + " years old")
print("This year you will be", age, "years old")
print(f"This year you will be {age} years old")
What year were you born?
1961
This year you will be 64 years old
This year you will be 64 years old
This year you will be 64 years old
Lists#
colours = ['hearts', 'spades', 'diamonds', 'clubs']
values = [2, 3, 4, 5, 6, 7, 8, 9, 10, 'knight', 'queen', 'king', 'ace']
dir(colours)
['__add__',
'__class__',
'__class_getitem__',
'__contains__',
'__delattr__',
'__delitem__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__getattribute__',
'__getitem__',
'__getstate__',
'__gt__',
'__hash__',
'__iadd__',
'__imul__',
'__init__',
'__init_subclass__',
'__iter__',
'__le__',
'__len__',
'__lt__',
'__mul__',
'__ne__',
'__new__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__reversed__',
'__rmul__',
'__setattr__',
'__setitem__',
'__sizeof__',
'__str__',
'__subclasshook__',
'append',
'clear',
'copy',
'count',
'extend',
'index',
'insert',
'pop',
'remove',
'reverse',
'sort']
colours + colours
['hearts',
'spades',
'diamonds',
'clubs',
'hearts',
'spades',
'diamonds',
'clubs']
len(colours)
4
len(values)
13
colours[0] # the first elements
'hearts'
colours[3]
'clubs'
colours[-1]
'clubs'
values.append('joker')
values
[2, 3, 4, 5, 6, 7, 8, 9, 10, 'knight', 'queen', 'king', 'ace', 'joker']
values.pop?
Signature: values.pop(index=-1, /)
Docstring:
Remove and return item at index (default last).
Raises IndexError if list is empty or index is out of range.
Type: builtin_function_or_method
values.pop()
'joker'
values
[2, 3, 4, 5, 6, 7, 8, 9, 10, 'knight', 'queen', 'king', 'ace']
colours
['hearts', 'spades', 'diamonds', 'clubs']
colours.sort()
colours
['clubs', 'diamonds', 'hearts', 'spades']
colours.reverse()
colours
['spades', 'hearts', 'diamonds', 'clubs']
Tuples#
card1 = (colours[0], values[0])
card1
('spades', 2)
dir(card1)
['__add__',
'__class__',
'__class_getitem__',
'__contains__',
'__delattr__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__getattribute__',
'__getitem__',
'__getnewargs__',
'__getstate__',
'__gt__',
'__hash__',
'__init__',
'__init_subclass__',
'__iter__',
'__le__',
'__len__',
'__lt__',
'__mul__',
'__ne__',
'__new__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__rmul__',
'__setattr__',
'__sizeof__',
'__str__',
'__subclasshook__',
'count',
'index']
card1.index(2)
1
Slicing#
values
[2, 3, 4, 5, 6, 7, 8, 9, 10, 'knight', 'queen', 'king', 'ace']
# list[start: end: step]
values[1: 5]
[3, 4, 5, 6]
values[0: 13: 2] # every second element
[2, 4, 6, 8, 10, 'queen', 'ace']
values[::2]
[2, 4, 6, 8, 10, 'queen', 'ace']
# the first 9 elements
values[:9]
[2, 3, 4, 5, 6, 7, 8, 9, 10]
# the last 4 elements
values[-4:]
['knight', 'queen', 'king', 'ace']
#cmopare
"Hello world"[-4:]
'orld'
Dictionaries#
d = {'a': 1, 'b': 2}
len(d)
2
d.keys()
dict_keys(['a', 'b'])
d.values()
dict_values([1, 2])
d['a']
1
d['b']
2
{'a': 1, 'b': 2} == {'b': 2, 'a': 1}
True
# Card game
game = {
'player1': [],
'player2': []
}
deck = [ ('hearts', 2), ('clubs', 4), ('diamonds', 10), ('spades', 5) ]
game['player1'].append(deck.pop())
print(game)
print(deck)
game['player2'].append(deck.pop())
print(game)
print(deck)
game['player1'].append(deck.pop())
print(game)
print(deck)
game['player2'].append(deck.pop())
print(game)
print(deck)
{'player1': [('spades', 5)], 'player2': []}
[('hearts', 2), ('clubs', 4), ('diamonds', 10)]
{'player1': [('spades', 5)], 'player2': [('diamonds', 10)]}
[('hearts', 2), ('clubs', 4)]
{'player1': [('spades', 5), ('clubs', 4)], 'player2': [('diamonds', 10)]}
[('hearts', 2)]
{'player1': [('spades', 5), ('clubs', 4)], 'player2': [('diamonds', 10), ('hearts', 2)]}
[]
game
{'player1': [('spades', 5), ('clubs', 4)],
'player2': [('diamonds', 10), ('hearts', 2)]}
Repetition#
for-loops#
colours
['spades', 'hearts', 'diamonds', 'clubs']
deck = []
for colour in colours:
print(colour)
for value in values:
print(value, end=' ')
card = (colour, value)
deck.append(card)
print()
spades
2 3 4 5 6 7 8 9 10 knight queen king ace
hearts
2 3 4 5 6 7 8 9 10 knight queen king ace
diamonds
2 3 4 5 6 7 8 9 10 knight queen king ace
clubs
2 3 4 5 6 7 8 9 10 knight queen king ace
len(deck)
52
#for x in game.keys():
for player in game:
print(player)
print(f"Player {player} has hand {game[player]}")
player1
Player player1 has hand [('spades', 5), ('clubs', 4)]
player2
Player player2 has hand [('diamonds', 10), ('hearts', 2)]
for x in game.items():
print(x)
('player1', [('spades', 5), ('clubs', 4)])
('player2', [('diamonds', 10), ('hearts', 2)])
for x in game.items():
player = x[0]
hand = x[1]
print(f"Player {player} has hand {hand}")
Player player1 has hand [('spades', 5), ('clubs', 4)]
Player player2 has hand [('diamonds', 10), ('hearts', 2)]
for x in game.items():
player, hand = x
print(f"Player {player} has hand {hand}")
Player player1 has hand [('spades', 5), ('clubs', 4)]
Player player2 has hand [('diamonds', 10), ('hearts', 2)]
for player, hand in game.items():
print(f"Player {player} has hand {hand}")
Player player1 has hand [('spades', 5), ('clubs', 4)]
Player player2 has hand [('diamonds', 10), ('hearts', 2)]
Branching#
if statements#
# game where largest sum of value wins
if False:
print('yes')
else:
print('no')
no
# sum up card values for player 1
value1 = 0
for card in game['player1']:
value1 = value1 + card[1]
print(value1)
9
# sum up card values for player 2
value2 = 0
for card in game['player2']:
value2 = value2 + card[1]
print(value2)
12
# The player with largest value wins
if value1 > value2:
print("Player1 wins")
else:
print("Player2 wins")
Player2 wins
Functions#
print
<function print(*args, sep=' ', end='\n', file=None, flush=False)>
print("Hello")
Hello
len
<function len(obj, /)>
len('abc')
3
len([1,2,])
2
len({'a': 1})
1
input
<bound method Kernel.raw_input of <ipykernel.ipkernel.IPythonKernel object at 0x71a69fe93620>>
input()
'hoho'
#dir()
dir(__builtins__)
['ArithmeticError',
'AssertionError',
'AttributeError',
'BaseException',
'BaseExceptionGroup',
'BlockingIOError',
'BrokenPipeError',
'BufferError',
'BytesWarning',
'ChildProcessError',
'ConnectionAbortedError',
'ConnectionError',
'ConnectionRefusedError',
'ConnectionResetError',
'DeprecationWarning',
'EOFError',
'Ellipsis',
'EncodingWarning',
'EnvironmentError',
'Exception',
'ExceptionGroup',
'False',
'FileExistsError',
'FileNotFoundError',
'FloatingPointError',
'FutureWarning',
'GeneratorExit',
'IOError',
'ImportError',
'ImportWarning',
'IndentationError',
'IndexError',
'InterruptedError',
'IsADirectoryError',
'KeyError',
'KeyboardInterrupt',
'LookupError',
'MemoryError',
'ModuleNotFoundError',
'NameError',
'None',
'NotADirectoryError',
'NotImplemented',
'NotImplementedError',
'OSError',
'OverflowError',
'PendingDeprecationWarning',
'PermissionError',
'ProcessLookupError',
'PythonFinalizationError',
'RecursionError',
'ReferenceError',
'ResourceWarning',
'RuntimeError',
'RuntimeWarning',
'StopAsyncIteration',
'StopIteration',
'SyntaxError',
'SyntaxWarning',
'SystemError',
'SystemExit',
'TabError',
'TimeoutError',
'True',
'TypeError',
'UnboundLocalError',
'UnicodeDecodeError',
'UnicodeEncodeError',
'UnicodeError',
'UnicodeTranslateError',
'UnicodeWarning',
'UserWarning',
'ValueError',
'Warning',
'ZeroDivisionError',
'_IncompleteInputError',
'__IPYTHON__',
'__build_class__',
'__debug__',
'__doc__',
'__import__',
'__loader__',
'__name__',
'__package__',
'__spec__',
'abs',
'aiter',
'all',
'anext',
'any',
'ascii',
'bin',
'bool',
'breakpoint',
'bytearray',
'bytes',
'callable',
'chr',
'classmethod',
'compile',
'complex',
'copyright',
'credits',
'delattr',
'dict',
'dir',
'display',
'divmod',
'enumerate',
'eval',
'exec',
'execfile',
'filter',
'float',
'format',
'frozenset',
'get_ipython',
'getattr',
'globals',
'hasattr',
'hash',
'help',
'hex',
'id',
'input',
'int',
'isinstance',
'issubclass',
'iter',
'len',
'license',
'list',
'locals',
'map',
'max',
'memoryview',
'min',
'next',
'object',
'oct',
'open',
'ord',
'pow',
'print',
'property',
'range',
'repr',
'reversed',
'round',
'runfile',
'set',
'setattr',
'slice',
'sorted',
'staticmethod',
'str',
'sum',
'super',
'tuple',
'type',
'vars',
'zip']
# define our own function, make this a function
"""
value1 = 0
for card in game['player1']:
value1 = value1 + card[1]
print(value1)
"""
"\nvalue1 = 0\nfor card in game['player1']:\n value1 = value1 + card[1]\nprint(value1)\n"
A function definition
start with the def keyword, a name, parentheses, colon
function body (indented)
values are passed to the function as arguments
parameters of a function are variables the hold these values
variables defined inside the function are not valid outside the function
The lines in a function body are executed when the function is called
the value of a function call is defined by a return statement in the function body
the None object represents absence of something, is returned in the absence of a return statement
global scope: variables not defined in any function local scope: variable defined inside a function (only valid locally)
a function can use value in the global scope
#define the function
def calculate_hand_value(card_game, player):
value = 0
for card in card_game[player]:
value = value + card[1]
print(value)
return value
# call function
calculate_hand_value(game, 'player1') #value of game is passed to function parameter card_game, 'player1' is passed to parameter player
calculate_hand_value(game, 'player2')
9
12
12
result = calculate_hand_value(game, 'player1')
result == 9
9
True
print(result)
9
print(value)
ace
# alternative with global game
def calculate_hand_value2(player):
value = 0
for card in game[player]:
value = value + card[1]
print(value)
return value
calculate_hand_value2('player1')
9
9
print?
Signature: print(*args, sep=' ', end='\n', file=None, flush=False)
Docstring:
Prints the values to a stream, or to sys.stdout by default.
sep
string inserted between values, default a space.
end
string appended after the last value, default a newline.
file
a file-like object (stream); defaults to the current sys.stdout.
flush
whether to forcibly flush the stream.
Type: builtin_function_or_method
print('Hello', 'world', end='') # args parameter will be the tuple ('Hello', 'world')
print('Hello', 'world', sep='-')
Hello worldHello-world
# previous example with keyword
# alternative with global game as an optional argument
def calculate_hand_value3(player, card_game=game):
"""
Calculate the value of the hand of player
"""
_value = 0
for _card in card_game[player]:
_value = _value + _card[1]
return _value
calculate_hand_value3?
Signature:
calculate_hand_value3(
player,
card_game={'player1': [('spades', 5), ('clubs', 4)], 'player2': [('diamonds', 10), ('hearts', 2)]},
)
Docstring: Calculate the value of the hand of player
File: /tmp/ipykernel_1077854/3892734418.py
Type: function
help(calculate_hand_value3)
Help on function calculate_hand_value3 in module __main__:
calculate_hand_value3(
player,
card_game={'player1': [('spades', 5), ('clubs', 4)], 'player2': [('diamonds', 10), ('hearts', 2)]}
)
Calculate the value of the hand of player
calculate_hand_value3('player1')
9
_value # only defined locally inside the function, not globally
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[120], line 1
----> 1 _value # only defined locally inside the function, not globally
NameError: name '_value' is not defined
Modules#
import hello
The value of __name__ is hello
dir(hello)
['__builtins__',
'__cached__',
'__doc__',
'__file__',
'__loader__',
'__name__',
'__package__',
'__spec__',
'hello_world',
'sys']
hello.hello_world()
Hello -f
Goodbye
import on a python file runs all code in it
definitions in the file are saved in so called namespace
# %load hello.py
import sys
def hello_world():
if len(sys.argv) > 1:
print("Hello", sys.argv[1])
else:
print("Hello")
print("Goodbye")
if __name__ == "__main__": #do not run this code during import
hello_world()
print("The value of __name__ is", __name__)
#import os
#dir(os)
import math
dir(math)
['__doc__',
'__file__',
'__loader__',
'__name__',
'__package__',
'__spec__',
'acos',
'acosh',
'asin',
'asinh',
'atan',
'atan2',
'atanh',
'cbrt',
'ceil',
'comb',
'copysign',
'cos',
'cosh',
'degrees',
'dist',
'e',
'erf',
'erfc',
'exp',
'exp2',
'expm1',
'fabs',
'factorial',
'floor',
'fma',
'fmod',
'frexp',
'fsum',
'gamma',
'gcd',
'hypot',
'inf',
'isclose',
'isfinite',
'isinf',
'isnan',
'isqrt',
'lcm',
'ldexp',
'lgamma',
'log',
'log10',
'log1p',
'log2',
'modf',
'nan',
'nextafter',
'perm',
'pi',
'pow',
'prod',
'radians',
'remainder',
'sin',
'sinh',
'sqrt',
'sumprod',
'tan',
'tanh',
'tau',
'trunc',
'ulp']
math.pi
3.141592653589793
math.sin(math.pi)
1.2246467991473532e-16
math.sin(math.pi/2)
1.0
#optional import
from math import pi, sin, cos
sin(pi/4)
0.7071067811865475
cos(pi/4)
0.7071067811865476
Files#
f = open('hello.txt', mode='r') # open for reading an existing file
#dir(f)
f.read()
'Hello\nGoodbye\n'
f.read()
''
f = open('hello.txt', mode='r') # open for reading an existing file
f.readable()
f.readline() # read one lnie at a tome
'Hello\n'
f.readline()
'Goodbye\n'
f.readline()
''
f = open('hello.txt', mode='r') # open for reading an existing file
f.readlines() # read the file into a list of lines
['Hello\n', 'Goodbye\n']
f = open('hello.txt', mode='r') # open for reading an existing file
for line in f:
#print(line.upper(), end='')
print(line.strip().upper())
HELLO
GOODBYE
new = open('newhello.txt', mode='w')
new.write("Hello")
new.write("World!")
6
!ls -l
total 3600
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 15308 maj 16 14:23 advanced-2025-05-16.ipynb
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 256100 apr 15 08:59 child_mortality_0_5_year_olds_dying_per_1000_born.csv
-rw-r--r-- 1 bb1000-vt25 bb1000-vt25 21434 apr 25 14:03 classes-2025-04-25.ipynb
-rw-r--r-- 1 bb1000-vt25 bb1000-vt25 5000 apr 8 15:58 data.txt
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 1816 mar 31 16:00 Demo.ipynb
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 298018 apr 15 08:58 gdp_pcap.csv
drwxrwxr-x 4 bb1000-vt25 bb1000-vt25 4096 maj 9 14:40 git-2025-05-09
drwxrwxr-x 6 bb1000-vt25 bb1000-vt25 4096 maj 19 16:26 git_demo
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 280 apr 1 08:49 hello.py
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 14 mar 31 16:46 hello.txt
drwxrwxr-x 3 bb1000-vt25 bb1000-vt25 4096 apr 28 16:43 htmlcov
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 241 apr 28 16:52 leap.py
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 149 mar 31 16:30 mult_table.py
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 35 apr 29 09:32 my_math.py
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 0 maj 20 10:21 newhello.txt
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 1332300 maj 20 10:20 Notes.ipynb
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 2750 apr 14 16:42 numbers.txt
-rw-r--r-- 1 bb1000-vt25 bb1000-vt25 41855 apr 11 13:55 numpy-2025-04-11.ipynb
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 21699 apr 11 13:24 numpy-2025-04-11.zip
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 18 apr 14 16:21 omdb.py
-rw-r--r-- 1 bb1000-vt25 bb1000-vt25 425009 apr 14 16:34 pandas-2025-04-11.ipynb
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 306031 apr 14 15:20 pandas-2025-04-11.zip
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 116 apr 8 09:31 plotdemo.py
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 335155 apr 15 09:01 pop.csv
drwxrwxr-x 2 bb1000-vt25 bb1000-vt25 4096 apr 29 10:42 __pycache__
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 493778 apr 15 10:21 rosling.png
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 18244 apr 29 10:53 testing-2025-04-29.ipynb
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 323 apr 28 16:34 test_leap.py
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 169 apr 29 09:32 test_my_math.py
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 323 apr 29 10:45 test_timestamps.py
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 316 apr 29 10:26 timestamps1.py
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 292 apr 29 10:38 timestamps2.py
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 640 apr 29 09:55 timestamps.py
-rw-r--r-- 1 bb1000-vt25 bb1000-vt25 6742 apr 14 14:49 TSLA.csv
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 113 apr 29 09:37 untitled.md
new.close()
!ls -l newhello.txt
-rw-rw-r-- 1 bb1000-vt25 bb1000-vt25 11 maj 20 10:21 newhello.txt
!cat newhello.txt
HelloWorld!
# use write method to get separate lines
with open('newhello.txt', 'w') as new:
new.write("Hello\n")
new.write("World!\n")
!cat newhello.txt
Hello
World!
# add text to end of a file
with open("newhello.txt", 'a') as f:
f.write("Goodbye")
!cat newhello.txt
Hello
World!
Goodbye
pathlib module#
import pathlib
ls /home/bb1000-vt25/Downloads/MOCK_DATA.csv
/home/bb1000-vt25/Downloads/MOCK_DATA.csv
# in windows C:\HOME\BB1000\DOWNLOADS\MOCK_DATA.csv
datafile = pathlib.Path.home() / 'Downloads' / 'MOCK_DATA.csv'
datafile
PosixPath('/home/bb1000-vt25/Downloads/MOCK_DATA.csv')
open(datafile).readline()
'id,first_name,last_name,email,gender,ip_address,employee_id,salary,department\n'
#compare mean salaries for different genders
all_lines = open(datafile).readlines()
gender_data = {} # {'gender': [salaries..]}
for line in all_lines[1:]:
fields = line.split(',') # fields are values of single row/line
gender = fields[4]
salary = int(fields[7])
if gender in gender_data: # is gender present as a key in the dictionary gender_data?
gender_data[gender].append(salary)
else:
gender_data[gender] = [salary]
gender_data.keys()
dict_keys(['Male', 'Genderfluid', 'Female', 'Genderqueer', 'Non-binary', 'Bigender', 'Polygender', 'Agender'])
for gender, salaries in gender_data.items():
mean = round(sum(salaries)/len(salaries))
print(gender, mean, len(salaries))
Male 84138 444
Genderfluid 95577 17
Female 86417 448
Genderqueer 86913 24
Non-binary 86858 17
Bigender 87399 20
Polygender 77018 18
Agender 96232 12
csv module#
import csv
#dir(csv)
for line in csv.reader(open(datafile)):
print(line)
break
['id', 'first_name', 'last_name', 'email', 'gender', 'ip_address', 'employee_id', 'salary', 'department']
csv.reader?
Docstring:
csv_reader = reader(iterable [, dialect='excel']
[optional keyword args])
for row in csv_reader:
process(row)
The "iterable" argument can be any object that returns a line
of input for each iteration, such as a file object or a list. The
optional "dialect" parameter is discussed below. The function
also accepts optional keyword arguments which override settings
provided by the dialect.
The returned object is an iterator. Each iteration returns a row
of the CSV file (which can span multiple input lines).
Type: builtin_function_or_method
all_lines = list(csv.reader(open(datafile)))
all_lines[1:5]
[['1',
'Lucius',
'Feehery',
'lfeehery0@wiley.com',
'Male',
'155.143.110.178',
'1',
'123759',
'Legal'],
['2',
'Melina',
'Jossel',
'mjossel1@slideshare.net',
'Genderfluid',
'238.182.167.147',
'2',
'91045',
'Support'],
['3',
'Davide',
'Allin',
'dallin2@com.com',
'Male',
'151.26.69.126',
'3',
'66863',
'Accounting'],
['4',
'Angeline',
'Got',
'agot3@amazon.com',
'Female',
'225.181.149.174',
'4',
'45217',
'Human Resources']]
csv.DictReader?
Init signature:
csv.DictReader(
f,
fieldnames=None,
restkey=None,
restval=None,
dialect='excel',
*args,
**kwds,
)
Docstring: <no docstring>
File: ~/miniconda3/envs/bb1000/lib/python3.13/csv.py
Type: type
Subclasses:
for line in c: # line will be a dictionary with header values as keys
print(line)
break
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[167], line 1
----> 1 for line in c: # line will be a dictionary with header values as keys
2 print(line)
3 break
NameError: name 'c' is not defined
gender_data = {} # {'gender': [salaries..]}
for line in csv.DictReader(open(datafile)):
salary = int(line['salary'])
gender = line['gender']
if gender in gender_data: # is gender present as a key in the dictionary gender_data?
gender_data[gender].append(salary)
else:
gender_data[gender] = [salary]
for gender, salaries in gender_data.items():
mean = round(sum(salaries)/len(salaries))
print(gender, mean, len(salaries))
Male 84138 444
Genderfluid 95577 17
Female 86417 448
Genderqueer 86913 24
Non-binary 86858 17
Bigender 87399 20
Polygender 77018 18
Agender 96232 12
# with defaultdict from the collections module
import collections
collections.defaultdict?
Init signature: collections.defaultdict(self, /, *args, **kwargs)
Docstring:
defaultdict(default_factory=None, /, [...]) --> dict with default factory
The default factory is called without arguments to produce
a new value when a key is not present, in __getitem__ only.
A defaultdict compares equal to a dict with the same items.
All remaining arguments are treated the same as if they were
passed to the dict constructor, including keyword arguments.
File: ~/miniconda3/envs/bb1000/lib/python3.13/collections/__init__.py
Type: type
Subclasses: FreezableDefaultDict
counter = collections.defaultdict(int)
int()
0
counter
defaultdict(int, {})
counter['newkey']
0
counter
defaultdict(int, {'newkey': 0})
counter['another key'] = counter['anohter key'] + 1
counter
defaultdict(int, {'newkey': 0, 'anohter key': 0, 'another key': 1})
# our previous example
#gender_data = {} # {'gender': [salaries..]}
gender_data = collections.defaultdict(list)
for line in csv.DictReader(open(datafile)):
salary = int(line['salary'])
gender = line['gender']
#if gender in gender_data: # is gender present as a key in the dictionary gender_data?
# gender_data[gender].append(salary)
#else:
# gender_data[gender] = [salary]
gender_data[gender].append(salary)
for gender, salaries in gender_data.items():
mean = round(sum(salaries)/len(salaries))
print(gender, mean, len(salaries))
Male 84138 444
Genderfluid 95577 17
Female 86417 448
Genderqueer 86913 24
Non-binary 86858 17
Bigender 87399 20
Polygender 77018 18
Agender 96232 12
def select_second(t):
return t[1]
# print employees by department sorted by last name
department_personel = collections.defaultdict(list)
for line in csv.DictReader(open(datafile)):
dept = line['department']
name = (line['first_name'], line['last_name'])
#print(line, dept, name, sep='\n')
#break
department_personel[dept].append(name)
for dept, names in department_personel.items():
names.sort(key=select_second)
print('Department:', dept)
for first, last in names:
print(f'\t{first} {last}')
break
Department: Legal
Alejoa Aleksankin
Hollie Attenborrow
Benetta Bangley
Arlena Broxton
Ferd Burriss
Jenna Callacher
Valdemar Canland
Dov Cleverly
Quinlan Coslett
Lucho Coules
Ronnie Cowthart
Marieann Daughtrey
Dacy De la croix
Tucker Deeming
Pris Deinhardt
Terri Dobbson
Homerus Donwell
Sile Dunderdale
Daniele Eloi
Horatius Etherington
Lucius Feehery
Marcile Fitzackerley
Valencia Galtone
Hugibert Garrie
Mozelle Gerant
Kacey Girodier
Bobinette Gratten
Ariela Greenstock
Freddie Gricks
Meaghan Guinness
Rheta Handrik
Maggi Huller
Nicholas Hum
Marti Jodlkowski
Allianora Kaasman
Hersh Karpenko
Marcos Kulic
Nap Ledur
Allix Lidgard
Humfried Lympany
Maynord Manterfield
Corella Mattussevich
Samson Mayman
Wald McCuthais
Klement McGeown
Madison Middler
Randy Moat
Dagmar Mote
Chantal Mumby
Peadar Murtell
Thorsten Muscott
Dione Norwich
Ive O'Codihie
Elysha Orrick
Gusella Peach
Cordie Peasgood
Tiphany Philpotts
Bobby Picard
Cordie Plaskitt
Hillie Porteous
Field Poulsom
Millisent Praten
Barris Puckinghorne
Reggy Raden
Lacee Rulten
Tersina Shaefer
Beverlee Sharper
Montague Sibbs
Maxwell Simeoni
Nita Stanborough
Welsh Stelle
Urbanus Sullly
Alex Szymoni
Rowen Taffrey
Alyosha Taggett
Dyan Talloe
Justen Tessington
Francisco Tomaselli
Urbano Trevear
Victoir Warsop
Meris Whalley
Ricardo Yeaman
# how to sort a list fo tuples?
example_list = [('c', 'b'), ('a', 'd'), ('a', 'c')]
example_list.sort()
example_list
[('a', 'c'), ('a', 'd'), ('c', 'b')]
example_list.sort?
Signature: example_list.sort(*, key=None, reverse=False)
Docstring:
Sort the list in ascending order and return None.
The sort is in-place (i.e. the list itself is modified) and stable (i.e. the
order of two equal elements is maintained).
If a key function is given, apply it once to each list item and sort them,
ascending or descending, according to their function values.
The reverse flag can be set to sort in descending order.
Type: builtin_function_or_method
example_list.sort(key=select_second)
example_list
[('c', 'b'), ('a', 'c'), ('a', 'd')]
csv.DictReader??
Init signature:
csv.DictReader(
f,
fieldnames=None,
restkey=None,
restval=None,
dialect='excel',
*args,
**kwds,
)
Docstring: <no docstring>
Source:
class DictReader:
def __init__(self, f, fieldnames=None, restkey=None, restval=None,
dialect="excel", *args, **kwds):
if fieldnames is not None and iter(fieldnames) is fieldnames:
fieldnames = list(fieldnames)
self._fieldnames = fieldnames # list of keys for the dict
self.restkey = restkey # key to catch long rows
self.restval = restval # default value for short rows
self.reader = reader(f, dialect, *args, **kwds)
self.dialect = dialect
self.line_num = 0
def __iter__(self):
return self
@property
def fieldnames(self):
if self._fieldnames is None:
try:
self._fieldnames = next(self.reader)
except StopIteration:
pass
self.line_num = self.reader.line_num
return self._fieldnames
@fieldnames.setter
def fieldnames(self, value):
self._fieldnames = value
def __next__(self):
if self.line_num == 0:
# Used only for its side effect.
self.fieldnames
row = next(self.reader)
self.line_num = self.reader.line_num
# unlike the basic reader, we prefer not to return blanks,
# because we will typically wind up with a dict full of None
# values
while row == []:
row = next(self.reader)
d = dict(zip(self.fieldnames, row))
lf = len(self.fieldnames)
lr = len(row)
if lf < lr:
d[self.restkey] = row[lf:]
elif lf > lr:
for key in self.fieldnames[lr:]:
d[key] = self.restval
return d
__class_getitem__ = classmethod(types.GenericAlias)
File: ~/miniconda3/envs/bb1000/lib/python3.13/csv.py
Type: type
Subclasses:
External libraries#
import numpy
#dir(numpy)
import numpy.linalg
dir(numpy.linalg)
['LinAlgError',
'__all__',
'__builtins__',
'__cached__',
'__doc__',
'__file__',
'__loader__',
'__name__',
'__package__',
'__path__',
'__spec__',
'_linalg',
'_umath_linalg',
'cholesky',
'cond',
'cross',
'det',
'diagonal',
'eig',
'eigh',
'eigvals',
'eigvalsh',
'inv',
'linalg',
'lstsq',
'matmul',
'matrix_norm',
'matrix_power',
'matrix_rank',
'matrix_transpose',
'multi_dot',
'norm',
'outer',
'pinv',
'qr',
'slogdet',
'solve',
'svd',
'svdvals',
'tensordot',
'tensorinv',
'tensorsolve',
'test',
'trace',
'vecdot',
'vector_norm']
numpy.linalg.solve?
Signature: numpy.linalg.solve(a, b)
Call signature: numpy.linalg.solve(*args, **kwargs)
Type: _ArrayFunctionDispatcher
String form: <function solve at 0x71a69c5f8ea0>
File: ~/miniconda3/envs/bb1000/lib/python3.13/site-packages/numpy/linalg/_linalg.py
Docstring:
Solve a linear matrix equation, or system of linear scalar equations.
Computes the "exact" solution, `x`, of the well-determined, i.e., full
rank, linear matrix equation `ax = b`.
Parameters
----------
a : (..., M, M) array_like
Coefficient matrix.
b : {(M,), (..., M, K)}, array_like
Ordinate or "dependent variable" values.
Returns
-------
x : {(..., M,), (..., M, K)} ndarray
Solution to the system a x = b. Returned shape is (..., M) if b is
shape (M,) and (..., M, K) if b is (..., M, K), where the "..." part is
broadcasted between a and b.
Raises
------
LinAlgError
If `a` is singular or not square.
See Also
--------
scipy.linalg.solve : Similar function in SciPy.
Notes
-----
Broadcasting rules apply, see the `numpy.linalg` documentation for
details.
The solutions are computed using LAPACK routine ``_gesv``.
`a` must be square and of full-rank, i.e., all rows (or, equivalently,
columns) must be linearly independent; if either is not true, use
`lstsq` for the least-squares best "solution" of the
system/equation.
.. versionchanged:: 2.0
The b array is only treated as a shape (M,) column vector if it is
exactly 1-dimensional. In all other instances it is treated as a stack
of (M, K) matrices. Previously b would be treated as a stack of (M,)
vectors if b.ndim was equal to a.ndim - 1.
References
----------
.. [1] G. Strang, *Linear Algebra and Its Applications*, 2nd Ed., Orlando,
FL, Academic Press, Inc., 1980, pg. 22.
Examples
--------
Solve the system of equations:
``x0 + 2 * x1 = 1`` and
``3 * x0 + 5 * x1 = 2``:
>>> import numpy as np
>>> a = np.array([[1, 2], [3, 5]])
>>> b = np.array([1, 2])
>>> x = np.linalg.solve(a, b)
>>> x
array([-1., 1.])
Check that the solution is correct:
>>> np.allclose(np.dot(a, x), b)
True
Class docstring:
Class to wrap functions with checks for __array_function__ overrides.
All arguments are required, and can only be passed by position.
Parameters
----------
dispatcher : function or None
The dispatcher function that returns a single sequence-like object
of all arguments relevant. It must have the same signature (except
the default values) as the actual implementation.
If ``None``, this is a ``like=`` dispatcher and the
``_ArrayFunctionDispatcher`` must be called with ``like`` as the
first (additional and positional) argument.
implementation : function
Function that implements the operation on NumPy arrays without
overrides. Arguments passed calling the ``_ArrayFunctionDispatcher``
will be forwarded to this (and the ``dispatcher``) as if using
``*args, **kwargs``.
Attributes
----------
_implementation : function
The original implementation passed in.
a = [[3, 0, 0], [1, 8, 0], [0, 4, -2]]
b = [30, 18, 2]
x = numpy.linalg.solve(a, b)
x
array([10., 1., 1.])
x[0] + 3*x[1] + x[2]
np.float64(14.0)
c = numpy.array([1, 3, 1])
c
array([1, 3, 1])
numpy.dot(x, c)
np.float64(14.0)
numpy.linspace(0, 1, 11)
array([0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1. ])
list(range(0, 11, 1))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
numpy.arange(0, 11, .1)
array([ 0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1. ,
1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2. , 2.1,
2.2, 2.3, 2.4, 2.5, 2.6, 2.7, 2.8, 2.9, 3. , 3.1, 3.2,
3.3, 3.4, 3.5, 3.6, 3.7, 3.8, 3.9, 4. , 4.1, 4.2, 4.3,
4.4, 4.5, 4.6, 4.7, 4.8, 4.9, 5. , 5.1, 5.2, 5.3, 5.4,
5.5, 5.6, 5.7, 5.8, 5.9, 6. , 6.1, 6.2, 6.3, 6.4, 6.5,
6.6, 6.7, 6.8, 6.9, 7. , 7.1, 7.2, 7.3, 7.4, 7.5, 7.6,
7.7, 7.8, 7.9, 8. , 8.1, 8.2, 8.3, 8.4, 8.5, 8.6, 8.7,
8.8, 8.9, 9. , 9.1, 9.2, 9.3, 9.4, 9.5, 9.6, 9.7, 9.8,
9.9, 10. , 10.1, 10.2, 10.3, 10.4, 10.5, 10.6, 10.7, 10.8, 10.9])
numpy.savetxt('numbers.txt', numpy.arange(0, 11, .1).reshape((11, 10)))
numbers = numpy.loadtxt('numbers.txt')
numbers
array([[ 0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9],
[ 1. , 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9],
[ 2. , 2.1, 2.2, 2.3, 2.4, 2.5, 2.6, 2.7, 2.8, 2.9],
[ 3. , 3.1, 3.2, 3.3, 3.4, 3.5, 3.6, 3.7, 3.8, 3.9],
[ 4. , 4.1, 4.2, 4.3, 4.4, 4.5, 4.6, 4.7, 4.8, 4.9],
[ 5. , 5.1, 5.2, 5.3, 5.4, 5.5, 5.6, 5.7, 5.8, 5.9],
[ 6. , 6.1, 6.2, 6.3, 6.4, 6.5, 6.6, 6.7, 6.8, 6.9],
[ 7. , 7.1, 7.2, 7.3, 7.4, 7.5, 7.6, 7.7, 7.8, 7.9],
[ 8. , 8.1, 8.2, 8.3, 8.4, 8.5, 8.6, 8.7, 8.8, 8.9],
[ 9. , 9.1, 9.2, 9.3, 9.4, 9.5, 9.6, 9.7, 9.8, 9.9],
[10. , 10.1, 10.2, 10.3, 10.4, 10.5, 10.6, 10.7, 10.8, 10.9]])
# corresponds to
value_list = []
for line in open('numbers.txt'):
value_list.append([])
for element in line.split():
value = float(element)
value_list[-1].append(value)
value_array= numpy.array(value_list)
value_array
array([[ 0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9],
[ 1. , 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9],
[ 2. , 2.1, 2.2, 2.3, 2.4, 2.5, 2.6, 2.7, 2.8, 2.9],
[ 3. , 3.1, 3.2, 3.3, 3.4, 3.5, 3.6, 3.7, 3.8, 3.9],
[ 4. , 4.1, 4.2, 4.3, 4.4, 4.5, 4.6, 4.7, 4.8, 4.9],
[ 5. , 5.1, 5.2, 5.3, 5.4, 5.5, 5.6, 5.7, 5.8, 5.9],
[ 6. , 6.1, 6.2, 6.3, 6.4, 6.5, 6.6, 6.7, 6.8, 6.9],
[ 7. , 7.1, 7.2, 7.3, 7.4, 7.5, 7.6, 7.7, 7.8, 7.9],
[ 8. , 8.1, 8.2, 8.3, 8.4, 8.5, 8.6, 8.7, 8.8, 8.9],
[ 9. , 9.1, 9.2, 9.3, 9.4, 9.5, 9.6, 9.7, 9.8, 9.9],
[10. , 10.1, 10.2, 10.3, 10.4, 10.5, 10.6, 10.7, 10.8, 10.9]])
numbers[:, : ]# all
numbers[:, -1 ] #last column
numbers[:1, :] # first row
numbers[:3, :3] # upper left 3x3 subblock
array([[0. , 0.1, 0.2],
[1. , 1.1, 1.2],
[2. , 2.1, 2.2]])
import time
import numpy
n = 512
a = numpy.ones((n, n))
b = numpy.ones((n, n))
c = numpy.zeros((n, n))
t1 = time.time()
for i in range(n):
for j in range(n):
for k in range(n):
c[i, j] += a[i, k]*b[k, j]
t2 = time.time()
print("Loop timing", t2-t1)
Loop timing 118.91819548606873
t1 = time.time()
c = a @ b
t2 = time.time()
print("Loop timing", t2-t1)
Loop timing 0.03766798973083496
arr = numbers[:3, :3]
arr
array([[0. , 0.1, 0.2],
[1. , 1.1, 1.2],
[2. , 2.1, 2.2]])
numpy.linalg.inv(arr)
---------------------------------------------------------------------------
LinAlgError Traceback (most recent call last)
Cell In[207], line 1
----> 1 numpy.linalg.inv(arr)
File ~/miniconda3/envs/bb1000/lib/python3.13/site-packages/numpy/linalg/_linalg.py:609, in inv(a)
606 signature = 'D->D' if isComplexType(t) else 'd->d'
607 with errstate(call=_raise_linalgerror_singular, invalid='call',
608 over='ignore', divide='ignore', under='ignore'):
--> 609 ainv = _umath_linalg.inv(a, signature=signature)
610 return wrap(ainv.astype(result_t, copy=False))
File ~/miniconda3/envs/bb1000/lib/python3.13/site-packages/numpy/linalg/_linalg.py:104, in _raise_linalgerror_singular(err, flag)
103 def _raise_linalgerror_singular(err, flag):
--> 104 raise LinAlgError("Singular matrix")
LinAlgError: Singular matrix
numpy.linalg.det(arr)
np.float64(0.0)
a = numpy.array([[3, 0, 0], [1, 8, 0], [0, 4, -2]])
b = numpy.array([30, 18, 2])
x = numpy.linalg.solve(a, b)
x
array([10., 1., 1.])
a @ x
array([30., 18., 2.])
numpy.linalg.inv(a) @ a @ x
array([10., 1., 1.])
# a @ x = b
# a(inv) @ a @ x = a(inv) @ b
# x = a(inv) @ b
numpy.linalg.inv(a) @ b
array([10., 1., 1.])
Matplotlib#
import matplotlib.pyplot as plt
x = numpy.arange(0, 2*3.1415, .1)
x
array([0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1. , 1.1, 1.2,
1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2. , 2.1, 2.2, 2.3, 2.4, 2.5,
2.6, 2.7, 2.8, 2.9, 3. , 3.1, 3.2, 3.3, 3.4, 3.5, 3.6, 3.7, 3.8,
3.9, 4. , 4.1, 4.2, 4.3, 4.4, 4.5, 4.6, 4.7, 4.8, 4.9, 5. , 5.1,
5.2, 5.3, 5.4, 5.5, 5.6, 5.7, 5.8, 5.9, 6. , 6.1, 6.2])
numpy.sin(x)
array([ 0. , 0.09983342, 0.19866933, 0.29552021, 0.38941834,
0.47942554, 0.56464247, 0.64421769, 0.71735609, 0.78332691,
0.84147098, 0.89120736, 0.93203909, 0.96355819, 0.98544973,
0.99749499, 0.9995736 , 0.99166481, 0.97384763, 0.94630009,
0.90929743, 0.86320937, 0.8084964 , 0.74570521, 0.67546318,
0.59847214, 0.51550137, 0.42737988, 0.33498815, 0.23924933,
0.14112001, 0.04158066, -0.05837414, -0.15774569, -0.2555411 ,
-0.35078323, -0.44252044, -0.52983614, -0.61185789, -0.68776616,
-0.7568025 , -0.81827711, -0.87157577, -0.91616594, -0.95160207,
-0.97753012, -0.993691 , -0.99992326, -0.99616461, -0.98245261,
-0.95892427, -0.92581468, -0.88345466, -0.83226744, -0.77276449,
-0.70554033, -0.63126664, -0.55068554, -0.46460218, -0.37387666,
-0.2794155 , -0.1821625 , -0.0830894 ])
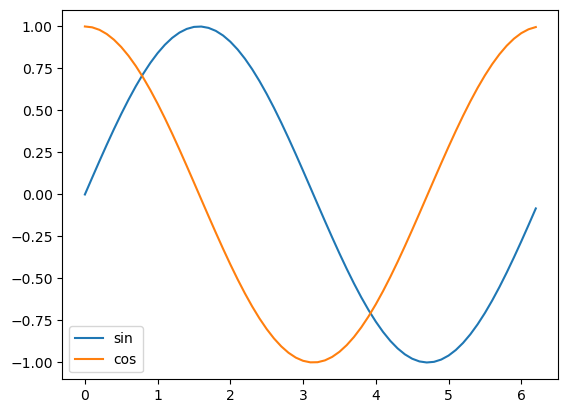
plt.plot(x, numpy.sin(x), label='sin')
plt.plot(x, numpy.cos(x), label='cos')
plt.legend()
plt.show()
Pandas#
import pandas as pd
s = pd.Series(range(4))/10
s
0 0.0
1 0.1
2 0.2
3 0.3
dtype: float64
s[1: 2]
1 0.1
dtype: float64
t = pd.Series(range(4), index=['a', 'b', 'c', 'd'])/10
t
a 0.0
b 0.1
c 0.2
d 0.3
dtype: float64
t['b': 'c']
b 0.1
c 0.2
dtype: float64
# indexing with lists
s[[0, 3]]
0 0.0
3 0.3
dtype: float64
t[['a', 'd']]
a 0.0
d 0.3
dtype: float64
#filtering
s > .1
0 False
1 False
2 True
3 True
dtype: bool
s[[False, True, True, False]]
1 0.1
2 0.2
dtype: float64
s[s > .1]
2 0.2
3 0.3
dtype: float64
s.mean()
np.float64(0.15000000000000002)
#dir(s)
Dataframes#
data = {'country': ['Belgium', 'France', 'Germany', 'Netherlands', 'United Kingdom'],
'population': [11.3, 64.3, 81.3, 16.9, 64.9],
'area': [30510, 671308, 357050, 41526, 244820],
'capital': ['Brussels', 'Paris', 'Berlin', 'Amsterdam', 'London']}
df = pd.DataFrame(data)
df
| country | population | area | capital | |
|---|---|---|---|---|
| 0 | Belgium | 11.3 | 30510 | Brussels |
| 1 | France | 64.3 | 671308 | Paris |
| 2 | Germany | 81.3 | 357050 | Berlin |
| 3 | Netherlands | 16.9 | 41526 | Amsterdam |
| 4 | United Kingdom | 64.9 | 244820 | London |
df.set_index('country')
| population | area | capital | |
|---|---|---|---|
| country | |||
| Belgium | 11.3 | 30510 | Brussels |
| France | 64.3 | 671308 | Paris |
| Germany | 81.3 | 357050 | Berlin |
| Netherlands | 16.9 | 41526 | Amsterdam |
| United Kingdom | 64.9 | 244820 | London |
df #unmodified
| country | population | area | capital | |
|---|---|---|---|---|
| 0 | Belgium | 11.3 | 30510 | Brussels |
| 1 | France | 64.3 | 671308 | Paris |
| 2 | Germany | 81.3 | 357050 | Berlin |
| 3 | Netherlands | 16.9 | 41526 | Amsterdam |
| 4 | United Kingdom | 64.9 | 244820 | London |
# equivalent to df = df.set_index('country')
df.set_index('country', inplace=True)
df
| population | area | capital | |
|---|---|---|---|
| country | |||
| Belgium | 11.3 | 30510 | Brussels |
| France | 64.3 | 671308 | Paris |
| Germany | 81.3 | 357050 | Berlin |
| Netherlands | 16.9 | 41526 | Amsterdam |
| United Kingdom | 64.9 | 244820 | London |
#select elements
df['capital']
country
Belgium Brussels
France Paris
Germany Berlin
Netherlands Amsterdam
United Kingdom London
Name: capital, dtype: object
df['capital']['France']
'Paris'
#alt
df.loc['France', 'capital']
'Paris'
# modify element
df['population']['Belgium'] = 11.4
/tmp/ipykernel_1077854/1863415940.py:2: FutureWarning: ChainedAssignmentError: behaviour will change in pandas 3.0!
You are setting values through chained assignment. Currently this works in certain cases, but when using Copy-on-Write (which will become the default behaviour in pandas 3.0) this will never work to update the original DataFrame or Series, because the intermediate object on which we are setting values will behave as a copy.
A typical example is when you are setting values in a column of a DataFrame, like:
df["col"][row_indexer] = value
Use `df.loc[row_indexer, "col"] = values` instead, to perform the assignment in a single step and ensure this keeps updating the original `df`.
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
df['population']['Belgium'] = 11.4
/tmp/ipykernel_1077854/1863415940.py:2: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
df['population']['Belgium'] = 11.4
df.loc['Belgium', 'population'] = 11.4
df
| population | area | capital | |
|---|---|---|---|
| country | |||
| Belgium | 11.4 | 30510 | Brussels |
| France | 64.3 | 671308 | Paris |
| Germany | 81.3 | 357050 | Berlin |
| Netherlands | 16.9 | 41526 | Amsterdam |
| United Kingdom | 64.9 | 244820 | London |
df.iloc[0, 0] = 11.5
df
| population | area | capital | |
|---|---|---|---|
| country | |||
| Belgium | 11.5 | 30510 | Brussels |
| France | 64.3 | 671308 | Paris |
| Germany | 81.3 | 357050 | Berlin |
| Netherlands | 16.9 | 41526 | Amsterdam |
| United Kingdom | 64.9 | 244820 | London |
df['density'] = df.population / df.area * 1000
df
| population | area | capital | density | |
|---|---|---|---|---|
| country | ||||
| Belgium | 11.5 | 30510 | Brussels | 0.376926 |
| France | 64.3 | 671308 | Paris | 0.095783 |
| Germany | 81.3 | 357050 | Berlin | 0.227699 |
| Netherlands | 16.9 | 41526 | Amsterdam | 0.406974 |
| United Kingdom | 64.9 | 244820 | London | 0.265093 |
df.density > .3
country
Belgium True
France False
Germany False
Netherlands True
United Kingdom False
Name: density, dtype: bool
df[df.density > .3]
| population | area | capital | density | |
|---|---|---|---|---|
| country | ||||
| Belgium | 11.5 | 30510 | Brussels | 0.376926 |
| Netherlands | 16.9 | 41526 | Amsterdam | 0.406974 |
df.area /= 1000
df
| population | area | capital | density | |
|---|---|---|---|---|
| country | ||||
| Belgium | 11.5 | 30.510 | Brussels | 0.376926 |
| France | 64.3 | 671.308 | Paris | 0.095783 |
| Germany | 81.3 | 357.050 | Berlin | 0.227699 |
| Netherlands | 16.9 | 41.526 | Amsterdam | 0.406974 |
| United Kingdom | 64.9 | 244.820 | London | 0.265093 |
df.plot()
<Axes: xlabel='country'>
df.plot(kind='bar')
<Axes: xlabel='country'>
# reading csv files
datafile
PosixPath('/home/bb1000-vt25/Downloads/MOCK_DATA.csv')
personel = pd.read_csv(datafile)
personel.salary.max()
np.int64(149702)
personel.salary.min()
np.int64(20157)
personel.salary.mean()
np.float64(85548.704)
#dir(personel)
personel.groupby('gender')['salary'].mean()
gender
Agender 96231.916667
Bigender 87399.050000
Female 86417.080357
Genderfluid 95576.764706
Genderqueer 86913.000000
Male 84138.439189
Non-binary 86857.529412
Polygender 77018.111111
Name: salary, dtype: float64
personel.groupby('gender')['salary'].mean().round()
gender
Agender 96232.0
Bigender 87399.0
Female 86417.0
Genderfluid 95577.0
Genderqueer 86913.0
Male 84138.0
Non-binary 86858.0
Polygender 77018.0
Name: salary, dtype: float64
personel.groupby('gender')['salary'].mean().round().astype(int)
gender
Agender 96232
Bigender 87399
Female 86417
Genderfluid 95577
Genderqueer 86913
Male 84138
Non-binary 86858
Polygender 77018
Name: salary, dtype: int64
# get 10 lowest salaries for females, lowest first
personel[personel.gender == 'Female'].sort_values('salary').head(10)
| id | first_name | last_name | gender | ip_address | employee_id | salary | department | ||
|---|---|---|---|---|---|---|---|---|---|
| 122 | 123 | Nettie | Jandak | njandak3e@icq.com | Female | 166.251.166.227 | 123 | 20317 | Marketing |
| 12 | 13 | Lonee | Staunton | lstauntonc@surveymonkey.com | Female | 138.24.99.81 | 13 | 20815 | Marketing |
| 155 | 156 | Cymbre | Balam | cbalam4b@spotify.com | Female | 55.156.47.9 | 156 | 20942 | Engineering |
| 339 | 340 | Anna-maria | Dadge | adadge9f@skyrock.com | Female | 91.173.33.3 | 340 | 21654 | Sales |
| 106 | 107 | Amye | Schofield | aschofield2y@globo.com | Female | 35.209.149.103 | 107 | 21930 | Services |
| 583 | 584 | Terri | Eat | teatg7@wsj.com | Female | 49.14.126.170 | 584 | 23226 | Research and Development |
| 286 | 287 | Lillis | Jude | ljude7y@reddit.com | Female | 119.211.41.215 | 287 | 23616 | Engineering |
| 145 | 146 | Karna | Eyton | keyton41@tripadvisor.com | Female | 41.142.223.103 | 146 | 23657 | Accounting |
| 19 | 20 | Noell | Gadney | ngadneyj@blinklist.com | Female | 218.219.155.4 | 20 | 23794 | Research and Development |
| 191 | 192 | Golda | Cogswell | gcogswell5b@jigsy.com | Female | 141.109.221.182 | 192 | 24087 | Support |
personel.plot(kind='box', column='salary', by='gender', vert=False)
salary Axes(0.125,0.11;0.775x0.77)
dtype: object
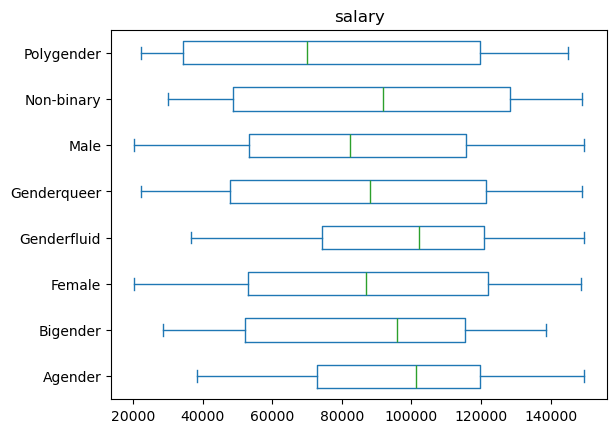
personel.groupby('gender')['salary'].describe()
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| gender | ||||||||
| Agender | 12.0 | 96231.916667 | 33622.378677 | 38414.0 | 72965.75 | 101333.5 | 119789.75 | 149702.0 |
| Bigender | 20.0 | 87399.050000 | 37020.164347 | 28684.0 | 52147.25 | 95875.5 | 115418.00 | 138593.0 |
| Female | 448.0 | 86417.080357 | 38494.376223 | 20317.0 | 52904.00 | 86963.5 | 121934.00 | 148645.0 |
| Genderfluid | 17.0 | 95576.764706 | 32896.581404 | 36697.0 | 74373.00 | 102223.0 | 120759.00 | 149576.0 |
| Genderqueer | 24.0 | 86913.000000 | 42049.463061 | 22271.0 | 47929.75 | 87971.5 | 121489.25 | 149019.0 |
| Male | 444.0 | 84138.439189 | 36493.311676 | 20157.0 | 53360.75 | 82365.0 | 115660.00 | 149676.0 |
| Non-binary | 17.0 | 86857.529412 | 42239.068737 | 29927.0 | 48726.00 | 91899.0 | 128314.00 | 148927.0 |
| Polygender | 18.0 | 77018.111111 | 44610.251539 | 22343.0 | 34399.75 | 69915.5 | 119753.25 | 145094.0 |
Notes on the lab#
x = numpy.arange(10)
y = numpy.arange(1, 20, 2)
len(x), len(y)
(10, 10)
# the coefficient matrix
sum_of_squares_x = x @ x
sum_of_x = sum(x)
sum_ones = len(x)
coefficient_matrix = numpy.array(
[
[ sum_of_squares_x, sum_of_x],
[ sum_of_x, len(x)]
])
coefficient_matrix
array([[285, 45],
[ 45, 10]])
# the right-hand side
rhs = numpy.array([ x @ y, sum(y)])
rhs
array([615, 100])
numpy.linalg.solve(coefficient_matrix, rhs)
array([2., 1.])
### oo plotting
fig, ax = plt.subplots()
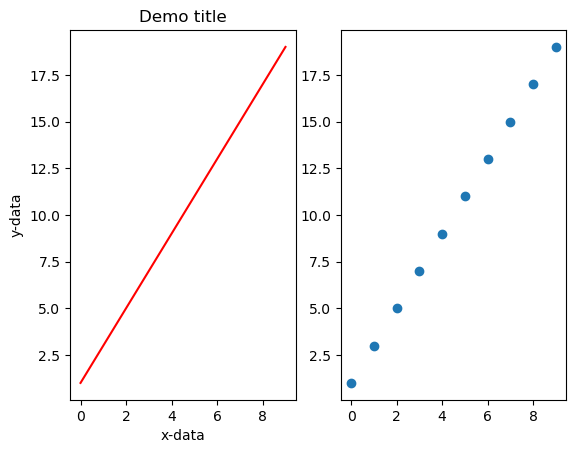
fig, (ax, ax2) = plt.subplots(ncols=2)
#dir(ax)
ax.set_title('Demo title')
ax.set_xlabel('x-data')
ax.set_ylabel('y-data')
ax2.scatter(x, y, marker='o')
ax.plot(x, y, color='red')
[<matplotlib.lines.Line2D at 0x71a6755d4b90>]
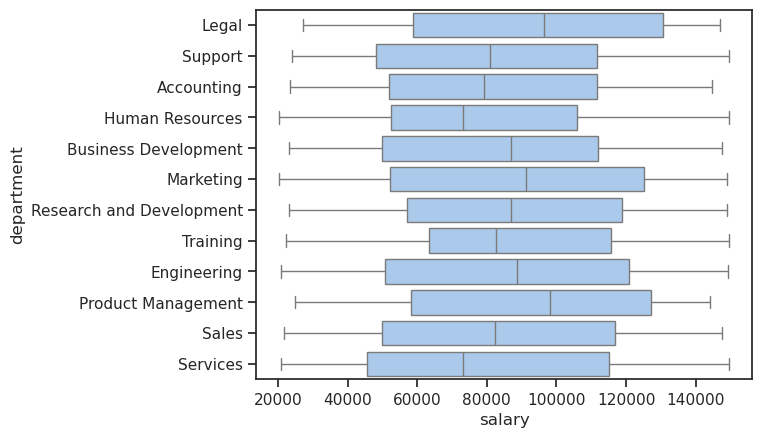
import seaborn
seaborn.set_theme(style="ticks", palette="pastel")
seaborn.boxplot(data=personel, y='department', x='salary')
<Axes: xlabel='salary', ylabel='department'>
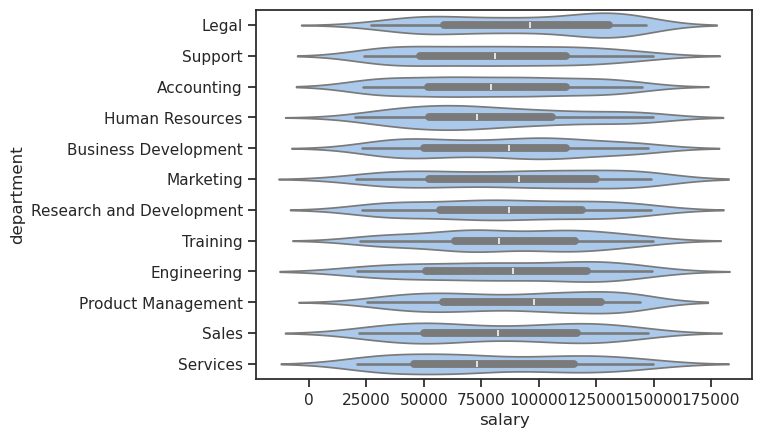
seaborn.violinplot(data=personel, y='department', x='salary')
<Axes: xlabel='salary', ylabel='department'>
Interactive plots#
import numpy as np
x = np.arange(-np.pi, np.pi, .1)
import matplotlib.pyplot as plt
plt.plot(x, np.sin(x))
plt.plot(x, np.sin(2*x))
[<matplotlib.lines.Line2D at 0x71a5f1dd9f90>]
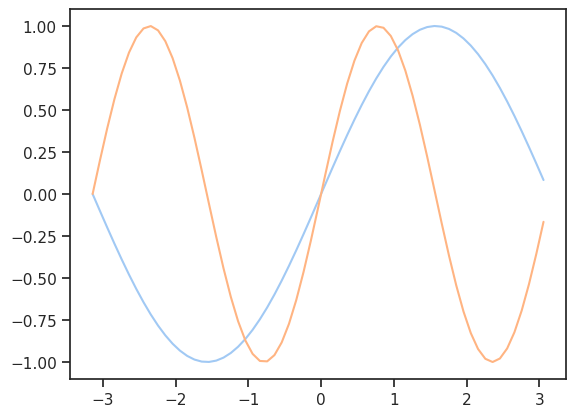
def sinplot(freq=1.0):
x = np.arange(-np.pi, np.pi, .1)
plt.plot(x, np.sin(freq*x))
sinplot(1)
sinplot(2)
#!conda install ipywidgets -y
#!conda install jupyterlab_widgets -y
import ipywidgets
freq_slider = ipywidgets.FloatSlider(min=1, max=2, value=1.5)
ipywidgets.interact(sinplot, freq=freq_slider)
<function __main__.sinplot(freq=1.0)>
plt.plot(x, np.exp(-x**2))
a = 2
plt.plot(x, np.exp(-a*x**2))
[<matplotlib.lines.Line2D at 0x71a5f0b6dbd0>]
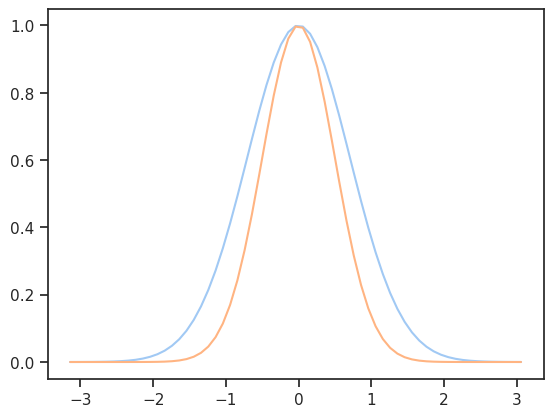
def gaussplot(a=1):
plt.plot(x, np.exp(-a*x**2))
gaussplot(a=1)
gaussplot(a=2)
from ipywidgets import interact, FloatSlider
interact(gaussplot, a=FloatSlider(min=1.0, max=2.0))
<function __main__.gaussplot(a=1)>
Reproducing gapminder presentation by Hans Rosling#
Youtube: https://www.ted.com/talks/hans_rosling_new_insights_on_poverty
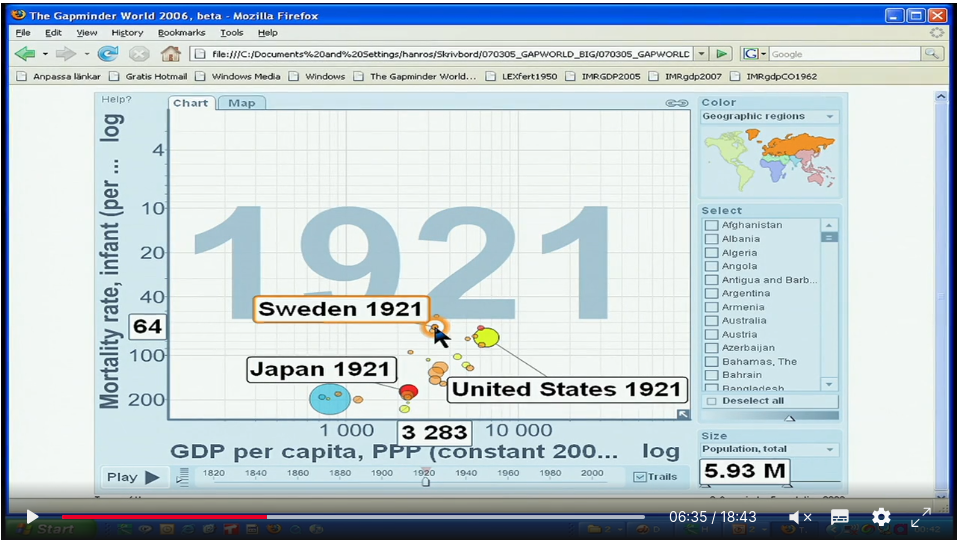
Can we reproduce the figure to some degree? Data is online at https://www.gapminder.org/data/
Scatterplot
x-value GDP per capita
y-values Infant mortality
each circle is a country
size reflects population
color reflects geographic region
import pandas as pd
pop = pd.read_csv('pop.csv').set_index('country')
pop
| 1800 | 1801 | 1802 | 1803 | 1804 | 1805 | 1806 | 1807 | 1808 | 1809 | ... | 2091 | 2092 | 2093 | 2094 | 2095 | 2096 | 2097 | 2098 | 2099 | 2100 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| country | |||||||||||||||||||||
| Afghanistan | 3.28M | 3.28M | 3.28M | 3.28M | 3.28M | 3.28M | 3.28M | 3.28M | 3.28M | 3.28M | ... | 124M | 125M | 126M | 126M | 127M | 128M | 128M | 129M | 130M | 130M |
| Angola | 1.57M | 1.57M | 1.57M | 1.57M | 1.57M | 1.57M | 1.57M | 1.57M | 1.57M | 1.57M | ... | 139M | 140M | 142M | 143M | 144M | 145M | 147M | 148M | 149M | 150M |
| Albania | 400k | 402k | 404k | 405k | 407k | 409k | 411k | 413k | 414k | 416k | ... | 1.34M | 1.32M | 1.3M | 1.29M | 1.27M | 1.25M | 1.23M | 1.22M | 1.2M | 1.18M |
| Andorra | 2650 | 2650 | 2650 | 2650 | 2650 | 2650 | 2650 | 2650 | 2650 | 2650 | ... | 52.8k | 52.1k | 51.5k | 50.8k | 50.2k | 49.6k | 49k | 48.4k | 47.8k | 47.2k |
| UAE | 40.2k | 40.2k | 40.2k | 40.2k | 40.2k | 40.2k | 40.2k | 40.2k | 40.2k | 40.2k | ... | 24.1M | 24.3M | 24.5M | 24.7M | 25M | 25.2M | 25.4M | 25.7M | 25.9M | 26.1M |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| Samoa | 47.3k | 47.3k | 47.3k | 47.3k | 47.3k | 47.3k | 47.3k | 47.2k | 47.2k | 47.2k | ... | 370k | 372k | 374k | 375k | 377k | 378k | 380k | 381k | 382k | 384k |
| Yemen | 2.59M | 2.59M | 2.59M | 2.59M | 2.59M | 2.59M | 2.59M | 2.59M | 2.59M | 2.59M | ... | 107M | 107M | 107M | 108M | 108M | 109M | 109M | 109M | 110M | 110M |
| South Africa | 1.45M | 1.45M | 1.46M | 1.46M | 1.47M | 1.47M | 1.48M | 1.49M | 1.49M | 1.5M | ... | 92.4M | 92.6M | 92.9M | 93.1M | 93.3M | 93.5M | 93.7M | 93.9M | 94.1M | 94.3M |
| Zambia | 747k | 758k | 770k | 782k | 794k | 806k | 818k | 831k | 843k | 856k | ... | 61.1M | 61.5M | 61.9M | 62.3M | 62.7M | 63.1M | 63.4M | 63.8M | 64.1M | 64.5M |
| Zimbabwe | 1.09M | 1.09M | 1.09M | 1.09M | 1.09M | 1.09M | 1.09M | 1.09M | 1.09M | 1.09M | ... | 36.3M | 36.4M | 36.5M | 36.6M | 36.7M | 36.8M | 36.9M | 37M | 37.1M | 37.2M |
197 rows × 301 columns
gdp = pd.read_csv('gdp_pcap.csv').set_index('country')
gdp
| 1800 | 1801 | 1802 | 1803 | 1804 | 1805 | 1806 | 1807 | 1808 | 1809 | ... | 2091 | 2092 | 2093 | 2094 | 2095 | 2096 | 2097 | 2098 | 2099 | 2100 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| country | |||||||||||||||||||||
| Afghanistan | 481 | 481 | 481 | 481 | 481 | 481 | 481 | 481 | 481 | 481 | ... | 4680 | 4790 | 4910 | 5020 | 5140 | 5260 | 5380 | 5510 | 5640 | 5780 |
| Angola | 373 | 374 | 376 | 378 | 379 | 381 | 383 | 385 | 386 | 388 | ... | 24.5k | 25k | 25.6k | 26.1k | 26.6k | 27.1k | 27.7k | 28.2k | 28.8k | 29.3k |
| Albania | 469 | 471 | 472 | 473 | 475 | 476 | 477 | 479 | 480 | 482 | ... | 54.5k | 55.1k | 55.7k | 56.3k | 56.9k | 57.4k | 58k | 58.6k | 59.2k | 59.8k |
| Andorra | 1370 | 1370 | 1370 | 1380 | 1380 | 1380 | 1390 | 1390 | 1390 | 1390 | ... | 79.9k | 80.2k | 80.4k | 80.7k | 81k | 81.3k | 81.5k | 81.8k | 82k | 82.3k |
| UAE | 1140 | 1150 | 1150 | 1150 | 1160 | 1160 | 1170 | 1170 | 1180 | 1180 | ... | 92.6k | 92.6k | 92.6k | 92.7k | 92.7k | 92.7k | 92.8k | 92.8k | 92.8k | 92.9k |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| Samoa | 1600 | 1600 | 1600 | 1600 | 1600 | 1600 | 1600 | 1600 | 1600 | 1600 | ... | 24k | 24.5k | 25k | 25.5k | 26k | 26.5k | 27k | 27.6k | 28.1k | 28.6k |
| Yemen | 1010 | 1010 | 1020 | 1020 | 1020 | 1020 | 1030 | 1030 | 1030 | 1030 | ... | 6170 | 6320 | 6470 | 6620 | 6780 | 6950 | 7120 | 7290 | 7470 | 7650 |
| South Africa | 1750 | 1730 | 1710 | 1690 | 1670 | 1590 | 1590 | 1720 | 1510 | 1470 | ... | 44.5k | 45.1k | 45.7k | 46.4k | 47k | 47.6k | 48.2k | 48.8k | 49.5k | 50.1k |
| Zambia | 533 | 535 | 536 | 537 | 539 | 539 | 541 | 543 | 543 | 545 | ... | 16.6k | 17k | 17.4k | 17.8k | 18.2k | 18.6k | 19k | 19.4k | 19.9k | 20.3k |
| Zimbabwe | 919 | 920 | 921 | 922 | 923 | 924 | 925 | 926 | 927 | 928 | ... | 9840 | 10.1k | 10.3k | 10.6k | 10.8k | 11.1k | 11.4k | 11.6k | 11.9k | 12.2k |
195 rows × 301 columns
childm = pd.read_csv('child_mortality_0_5_year_olds_dying_per_1000_born.csv').set_index('country')
childm
| 1800 | 1801 | 1802 | 1803 | 1804 | 1805 | 1806 | 1807 | 1808 | 1809 | ... | 2091 | 2092 | 2093 | 2094 | 2095 | 2096 | 2097 | 2098 | 2099 | 2100 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| country | |||||||||||||||||||||
| Afghanistan | 469.0 | 469.0 | 469.0 | 469.0 | 469.0 | 469.0 | 470.0 | 470.0 | 470.0 | 470.0 | ... | 12.60 | 12.40 | 12.20 | 12.00 | 11.80 | 11.60 | 11.50 | 11.30 | 11.10 | 11.10 |
| Angola | 486.0 | 486.0 | 486.0 | 486.0 | 486.0 | 486.0 | 486.0 | 486.0 | 486.0 | 486.0 | ... | 17.70 | 17.50 | 17.30 | 17.10 | 17.00 | 16.80 | 16.60 | 16.40 | 16.30 | 16.30 |
| Albania | 375.0 | 375.0 | 375.0 | 375.0 | 375.0 | 375.0 | 375.0 | 375.0 | 375.0 | 375.0 | ... | 2.32 | 2.30 | 2.27 | 2.24 | 2.22 | 2.19 | 2.16 | 2.14 | 2.11 | 2.11 |
| Andorra | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | 0.86 | 0.84 | 0.83 | 0.81 | 0.80 | 0.79 | 0.78 | 0.77 | 0.76 | 0.76 |
| UAE | 434.0 | 434.0 | 434.0 | 434.0 | 434.0 | 434.0 | 434.0 | 434.0 | 434.0 | 434.0 | ... | 2.31 | 2.29 | 2.26 | 2.24 | 2.22 | 2.19 | 2.17 | 2.15 | 2.13 | 2.13 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| Samoa | 471.0 | 468.0 | 465.0 | 461.0 | 458.0 | 455.0 | 452.0 | 449.0 | 446.0 | 443.0 | ... | 3.73 | 3.70 | 3.67 | 3.65 | 3.62 | 3.59 | 3.56 | 3.54 | 3.51 | 3.51 |
| Yemen | 540.0 | 540.0 | 540.0 | 540.0 | 540.0 | 540.0 | 540.0 | 540.0 | 540.0 | 540.0 | ... | 14.30 | 14.10 | 13.80 | 13.60 | 13.40 | 13.20 | 13.00 | 12.80 | 12.60 | 12.60 |
| South Africa | 398.0 | 398.0 | 398.0 | 398.0 | 398.0 | 398.0 | 398.0 | 398.0 | 398.0 | 398.0 | ... | 10.50 | 10.40 | 10.20 | 10.10 | 9.95 | 9.82 | 9.68 | 9.55 | 9.42 | 9.42 |
| Zambia | 410.0 | 410.0 | 410.0 | 410.0 | 410.0 | 410.0 | 410.0 | 410.0 | 410.0 | 410.0 | ... | 12.50 | 12.30 | 12.20 | 12.10 | 11.90 | 11.80 | 11.70 | 11.60 | 11.40 | 11.40 |
| Zimbabwe | 396.0 | 396.0 | 396.0 | 396.0 | 396.0 | 396.0 | 396.0 | 396.0 | 396.0 | 396.0 | ... | 14.60 | 14.50 | 14.40 | 14.30 | 14.20 | 14.10 | 13.90 | 13.80 | 13.70 | 13.70 |
197 rows × 301 columns
x = gdp.loc[['Sweden', 'Norway', 'Denmark'], '1921']
y = childm.loc[['Sweden', 'Norway', 'Denmark'], '1921']
x
country
Sweden 5200
Norway 4830
Denmark 6980
Name: 1921, dtype: object
y
country
Sweden 84.6
Norway 71.8
Denmark 91.3
Name: 1921, dtype: float64
plt.scatter(x, -np.log(y))
<matplotlib.collections.PathCollection at 0x71a5e9a5dbd0>
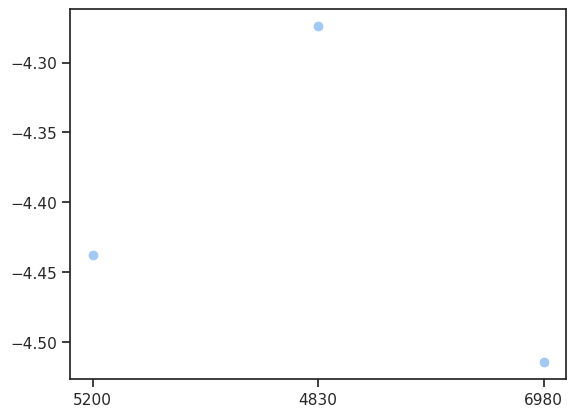
len(gdp), len(childm)
(195, 197)
df = pd.DataFrame()
df['GDP'] = gdp.loc[:, '1921']
df['Child mortality'] = childm.loc[:, '1921']
df['Population'] = pop.loc[: ,'1921']
df
| GDP | Child mortality | Population | |
|---|---|---|---|
| country | |||
| Afghanistan | 908 | 465.0 | 10.6M |
| Angola | 776 | 465.0 | 2.91M |
| Albania | 820 | 359.0 | 943k |
| Andorra | 4870 | NaN | 5610 |
| UAE | 2520 | 416.0 | 57.3k |
| ... | ... | ... | ... |
| Samoa | 2430 | 204.0 | 40.7k |
| Yemen | 1420 | 517.0 | 3.49M |
| South Africa | 2220 | 381.0 | 7.3M |
| Zambia | 799 | 392.0 | 1.48M |
| Zimbabwe | 731 | 379.0 | 1.56M |
195 rows × 3 columns
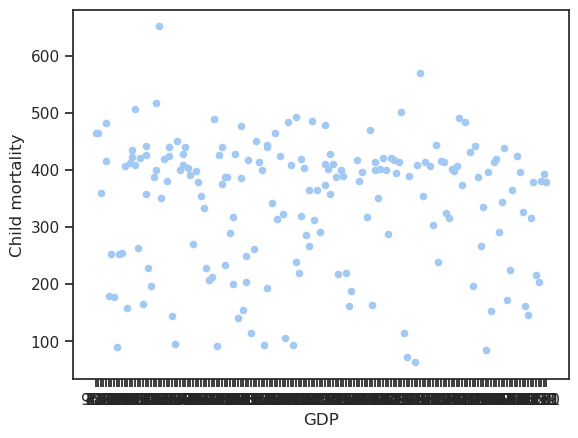
df.plot.scatter(x='GDP', y='Child mortality')
<Axes: xlabel='GDP', ylabel='Child mortality'>
Update#
make numeric columns#
How to we translate
k -> \(10^3\)
M -> \(10^6\)
B -> \(10^9\)
in a systematic way?
Consider 3.g. 10.6M meaning \(10.6*10^6\)
A function that that takes the string and splits off the final character
def convert(x: str) -> float:
factors = {'k': 10**3, 'M': 10**6, 'B': 10**9}
try:
if x[-1] in factors:
return float(x[:-1]) * factors[x[-1]]
else:
return float(x)
except TypeError:
# do nothing
return x
convert(2.0), convert('3k'), convert('4M'), convert('1B')
(2.0, 3000.0, 4000000.0, 1000000000.0)
The buildin function map applies a function on a sequence of values
for x in map(convert, [2.0, '3k', '4M', '1B']):
print(x)
2.0
3000.0
4000000.0
1000000000.0
In a similar vein pandas has a map method that is applied to its members
df['Population'].map(convert)
country
Afghanistan 10600000.0
Angola 2910000.0
Albania 943000.0
Andorra 5610.0
UAE 57300.0
...
Samoa 40700.0
Yemen 3490000.0
South Africa 7300000.0
Zambia 1480000.0
Zimbabwe 1560000.0
Name: Population, Length: 195, dtype: float64
Apply to and repalce all
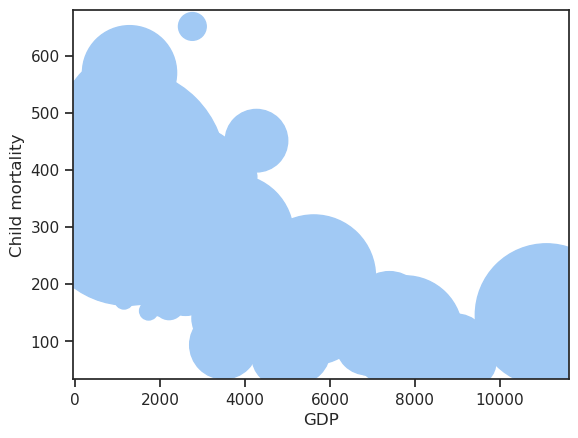
df = df.map(convert)
to let the population represent be proportional to the area of a circle in the plot we scale it further with the square root
df['Population'] = np.sqrt(df['Population'])
df
| GDP | Child mortality | Population | |
|---|---|---|---|
| country | |||
| Afghanistan | 908.0 | 465.0 | 3255.764119 |
| Angola | 776.0 | 465.0 | 1705.872211 |
| Albania | 820.0 | 359.0 | 971.081871 |
| Andorra | 4870.0 | NaN | 74.899933 |
| UAE | 2520.0 | 416.0 | 239.374184 |
| ... | ... | ... | ... |
| Samoa | 2430.0 | 204.0 | 201.742410 |
| Yemen | 1420.0 | 517.0 | 1868.154169 |
| South Africa | 2220.0 | 381.0 | 2701.851217 |
| Zambia | 799.0 | 392.0 | 1216.552506 |
| Zimbabwe | 731.0 | 379.0 | 1248.999600 |
195 rows × 3 columns
fix,ax = plt.subplots()
df.plot.scatter(x='GDP', y='Child mortality', s='Population', ax=ax)
<Axes: xlabel='GDP', ylabel='Child mortality'>
# scale some more
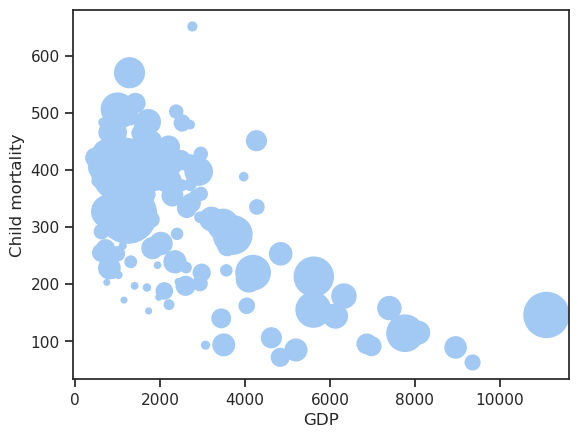
df['Population'] /= 10
df
| GDP | Child mortality | Population | |
|---|---|---|---|
| country | |||
| Afghanistan | 908.0 | 465.0 | 325.576412 |
| Angola | 776.0 | 465.0 | 170.587221 |
| Albania | 820.0 | 359.0 | 97.108187 |
| Andorra | 4870.0 | NaN | 7.489993 |
| UAE | 2520.0 | 416.0 | 23.937418 |
| ... | ... | ... | ... |
| Samoa | 2430.0 | 204.0 | 20.174241 |
| Yemen | 1420.0 | 517.0 | 186.815417 |
| South Africa | 2220.0 | 381.0 | 270.185122 |
| Zambia | 799.0 | 392.0 | 121.655251 |
| Zimbabwe | 731.0 | 379.0 | 124.899960 |
195 rows × 3 columns
df.plot.scatter(x='GDP', y='Child mortality', s='Population')
<Axes: xlabel='GDP', ylabel='Child mortality'>
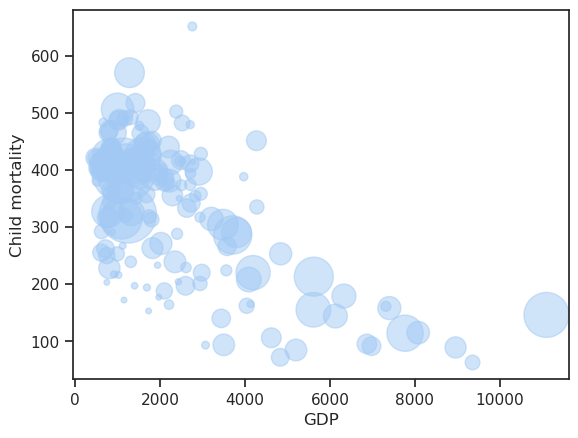
To get some transparency the alpha keyword can be used.
df.plot.scatter(
x='GDP',
y='Child mortality',
s='Population',
alpha=0.5
)
<Axes: xlabel='GDP', ylabel='Child mortality'>
The original figure has logarithmic scales
df.plot.scatter(
x='GDP',
y='Child mortality',
s='Population',
alpha=0.5,
logx=True,
logy=True,
)
<Axes: xlabel='GDP', ylabel='Child mortality'>
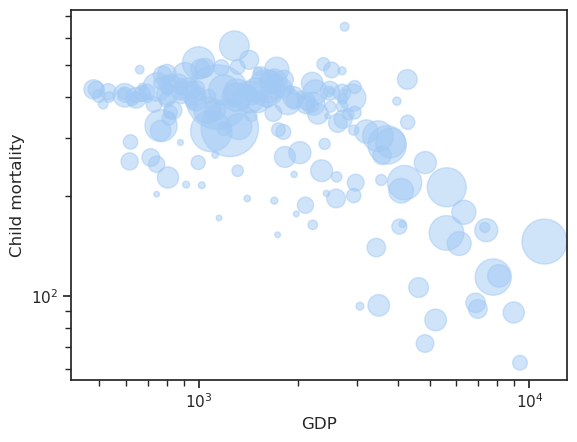
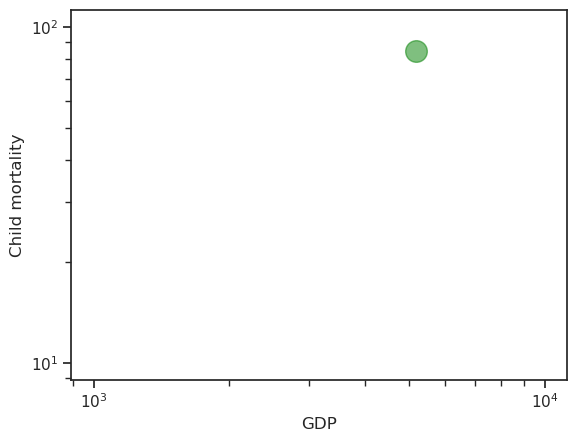
Where are we in all this?
df.plot.scatter(
x='GDP',
y='Child mortality',
s='Population',
alpha=0.5,
logx=True,
logy=True,
)
df.loc[['Sweden']].plot.scatter(
x='GDP',
y='Child mortality',
s='Population',
alpha=0.5,
logx=True,
logy=True,
c='green',
)
<Axes: xlabel='GDP', ylabel='Child mortality'>
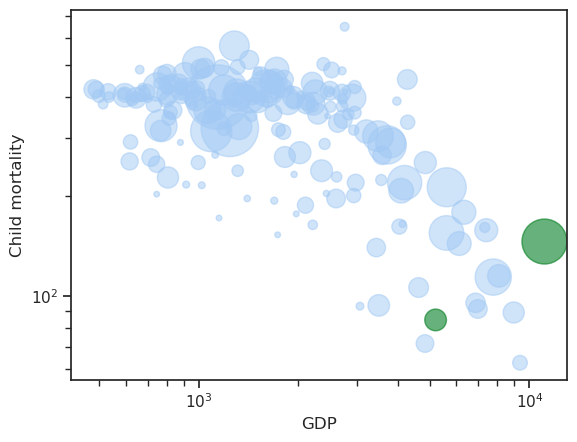
As we get more advanced and attach more things it is wise to work with the Axes objects directly
fig, ax = plt.subplots()
df.plot.scatter(
x='GDP',
y='Child mortality',
s='Population',
alpha=0.5,
logx=True,
logy=True,
ax=ax,
)
df.loc[['Sweden', 'USA']].plot.scatter(
x='GDP',
y='Child mortality',
s='Population',
alpha=0.5,
logx=True,
logy=True,
c='green',
ax=ax
)
<Axes: xlabel='GDP', ylabel='Child mortality'>
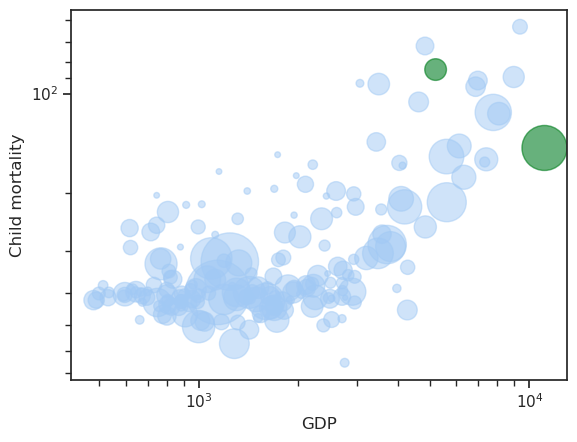
The original has inverted y axis (so that we plot increasing health vs increasing wealth)
fig, ax = plt.subplots()
df.plot.scatter(
x='GDP',
y='Child mortality',
s='Population',
alpha=0.5,
logx=True,
logy=True,
ax=ax,
)
df.loc[['Sweden', 'USA']].plot.scatter(
x='GDP',
y='Child mortality',
s='Population',
alpha=0.5,
logx=True,
logy=True,
c='green',
ax=ax
)
ax.invert_yaxis()
Set some text labels for the selected countries, and background year
selected = ['Sweden', 'USA']
fig, ax = plt.subplots()
df.plot.scatter(
x='GDP',
y='Child mortality',
s='Population',
alpha=0.5,
logx=True,
logy=True,
ax=ax,
)
df.loc[selected].plot.scatter(
x='GDP',
y='Child mortality',
s='Population',
alpha=0.5,
logx=True,
logy=True,
c='green',
ax=ax
)
ax.invert_yaxis()
for country in selected:
x = df.loc[country, 'GDP']
y = df.loc[country, 'Child mortality']
ax.text(1.1*x, y, country, bbox={'boxstyle': 'round', 'facecolor': 'wheat'})
ax.text(.5, .5, '1921', transform=ax.transAxes, fontsize=100, color='gray', alpha=0.25, ha='center', va='center')
Text(0.5, 0.5, '1921')
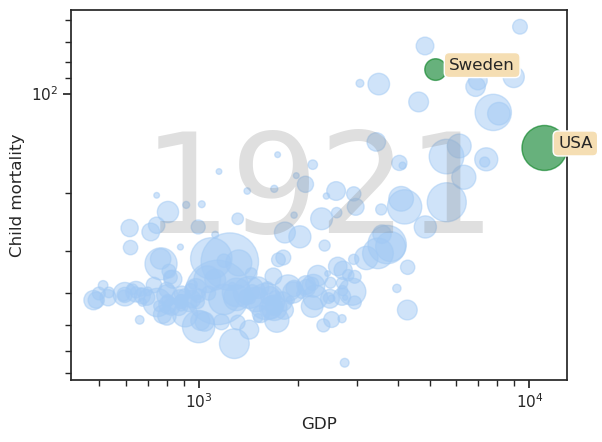
Set values on the axis for the selected countries
selected = ['Sweden', 'USA']
fig, ax = plt.subplots()
df.plot.scatter(
x='GDP',
y='Child mortality',
s='Population',
alpha=0.5,
logx=True,
logy=True,
ax=ax,
)
df.loc[selected].plot.scatter(
x='GDP',
y='Child mortality',
s='Population',
alpha=0.5,
logx=True,
logy=True,
c='green',
ax=ax
)
ax.invert_yaxis()
for country in selected:
x = df.loc[country, 'GDP']
y = df.loc[country, 'Child mortality']
ax.text(1.1*x, y, country, bbox={'boxstyle': 'round', 'facecolor': 'wheat'})
ax.text(.5, .5, '1921', transform=ax.transAxes, fontsize=100, color='gray', alpha=0.25, ha='center', va='center')
ax.set_xticks(df.loc[selected, 'GDP'], labels = [str(int(x)) for x in df.loc[selected, 'GDP']], rotation=90)
ax.set_yticks(df.loc[selected, 'Child mortality'], labels = [str(int(y)) for y in df.loc[selected, 'Child mortality']])
ax.grid(True)
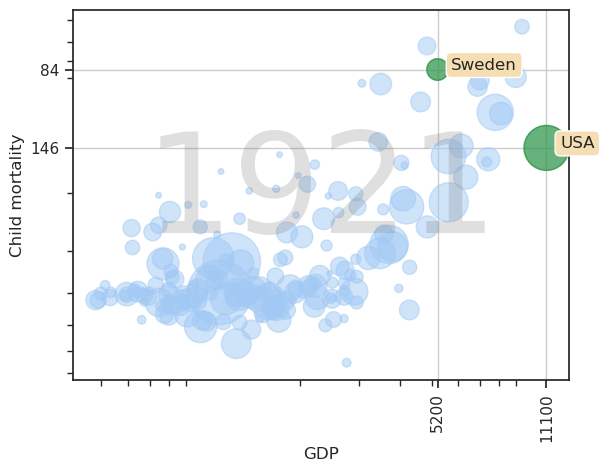
Finally we put in a historical perspective so that all years fit in the graph
selected = ['Sweden', 'USA']
fig, ax = plt.subplots()
df.plot.scatter(
x='GDP',
y='Child mortality',
s='Population',
alpha=0.5,
logx=True,
logy=True,
ax=ax,
)
df.loc[selected].plot.scatter(
x='GDP',
y='Child mortality',
s='Population',
alpha=0.5,
logx=True,
logy=True,
c='green',
ax=ax
)
for country in selected:
x = df.loc[country, 'GDP']
y = df.loc[country, 'Child mortality']
ax.text(1.1*x, y, country, bbox={'boxstyle': 'round', 'facecolor': 'wheat'})
ax.text(.5, .5, '1921', transform=ax.transAxes, fontsize=100, color='gray', alpha=0.25, ha='center', va='center')
ax.set_xticks(df.loc[selected, 'GDP'], labels = [str(int(x)) for x in df.loc[selected, 'GDP']], rotation=90)
ax.set_yticks(df.loc[selected, 'Child mortality'], labels = [str(int(y)) for y in df.loc[selected, 'Child mortality']])
ax.grid(True)
x_min = gdp.map(convert).min(axis=None)
x_max = gdp.map(convert).max(axis=None)
y_min = childm.map(convert).min(axis=None)
y_max = childm.map(convert).max(axis=None)
ax.set_xlim(x_min, x_max)
ax.set_ylim(y_min, y_max)
ax.invert_yaxis()
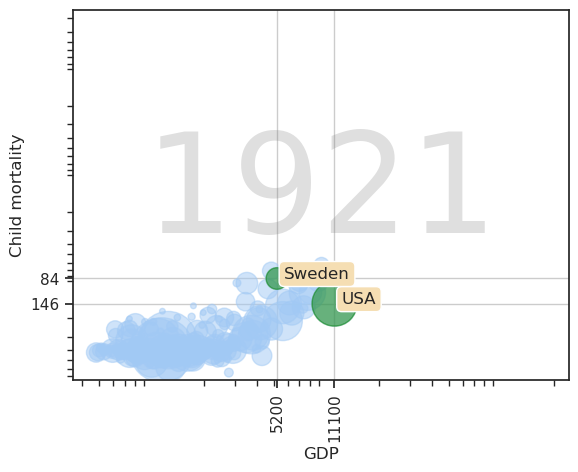
Challenges:
Make a movie of frames
Make a slider for the chosen year
Classes#
str1 = "Hello world!"
print(str1)
Hello world!
str1.upper()
"""
Implies that there is a upper method in the str class
class str:
def upper(self):
returns a new string replacing lower with upper case
"""
'\nImplies that there is a upper method in the str class\n\nclass str:\n def upper(self):\n returns a new string replacing lower with upper case\n\n'
str1.upper?
Signature: str1.upper()
Docstring: Return a copy of the string converted to uppercase.
Type: builtin_function_or_method
str.upper
<method 'upper' of 'str' objects>
str.upper?
Signature: str.upper(self, /)
Docstring: Return a copy of the string converted to uppercase.
Type: method_descriptor
str.upper(str1) # call the upper function of the str class with str1 as argument
'HELLO WORLD!'
str1.upper() # whatever class str1 belongs to, call its upper method with str1 as the first argument (usually declared with the name self)
'HELLO WORLD!'
# example
class Person:
"""
Datatype for personal data
"""
def __init__(self, given_name, surname):
self.given_name = given_name
self.surname = surname
def __str__(self): # usually a nicely readable string representation of the object
return f"Person: {self.given_name} {self.surname}"
def __repr__(self): # usually a unique accurate representation of an object
return f"Person('{self.given_name}', '{self.surname}')"
Person("Joe", "H.")
Person('Joe', 'H.')
Person('Joe', 'H.')
Person('Joe', 'H.')
Person?
Init signature: Person(given_name, surname)
Docstring: Datatype for personal data
Type: type
Subclasses:
type(int)
type
int()
0
type(int())
int
Person('Jane', 'Smith')
Person('Jane', 'Smith')
p=Person('Jane', 'Smith')
type(p)
__main__.Person
dir(p)
['__class__',
'__delattr__',
'__dict__',
'__dir__',
'__doc__',
'__eq__',
'__firstlineno__',
'__format__',
'__ge__',
'__getattribute__',
'__getstate__',
'__gt__',
'__hash__',
'__init__',
'__init_subclass__',
'__le__',
'__lt__',
'__module__',
'__ne__',
'__new__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__setattr__',
'__sizeof__',
'__static_attributes__',
'__str__',
'__subclasshook__',
'__weakref__',
'given_name',
'surname']
p.given_name
'Jane'
p.surname
'Smith'
print(p)
Person: Jane Smith
str(p) # delegates to p.__str__()
'Person: Jane Smith'
p.__str__()
'Person: Jane Smith'
p.given_name = "John"
print(p)
Person: John Smith
p
Person('John', 'Smith')
class Person:
"""
Datatype for personal data
"""
number = 0 # class attribute
def __init__(self, given_name, surname):
self.given_name = given_name # instance attribute
self.surname = surname
self.__class__.number += 1
def __str__(self): # usually a nicely readable string representation of the object
return f"Person: {self.given_name} {self.surname}"
def __repr__(self): # usually a unique accurate representation of an object
return f"Person('{self.given_name}', '{self.surname}')"
def display_person(self):
print(f"{self.surname}, {self.given_name}")
p1 = Person("Jane", "Smith")
p2 = Person("John", "Smith") # two different instances of class Person
p1.display_person()
p2.display_person()
Smith, Jane
Smith, John
p1.number
2
p2.number
2
Person.number
2
chosen_attribute = "given_name"
p1.__getattribute__(chosen_attribute)
'Jane'
# Addition operator +
2 + 3
5
"ab" + "cd"
'abcd'
[1] + [2]
[1, 2]
# Example: complex number
class MyComplex:
"""
Implements complex numbers in Python
"""
def __init__(self, re=0, im=0):
self.re = float(re)
self.im = float(im)
def __repr__(self):
return f"MyComplex({self.re}, {self.im})"
def __str__(self):
return f"{self.re} + {self.im}i"
# def __add__(left, right)
def __add__(self, other):
new_z = MyComplex(self.re + other.re, self.im + other.im)
return new_z
z = MyComplex()
z
MyComplex(0.0, 0.0)
z.re
0.0
z.im
0.0
str(z)
'0.0 + 0.0i'
z1 = MyComplex(1, 2)
z2 = MyComplex(3, 4)
z1 + z2
MyComplex(4.0, 6.0)
print(z1 + z2)
4.0 + 6.0i
Inheritance#
class Employee(Person):
"An employee class, derives from Person"
number = 0
def __init__(self, given_name, surname, salary):
#Person.__init__(self, given_name, surname)
super().__init__(given_name, surname)
self.salary = salary
e = Employee("Olav", "Vahtras", 0)
e.display_person()
Vahtras, Olav
e.number
1
dir(e)[0]
'__class__'
e.__class__
__main__.Employee
Testing#
assert True
assert False
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
Cell In[460], line 1
----> 1 assert False
AssertionError:
%%file test_my_math.py
from my_math import my_add
from pytest import approx
def test_my_add():
assert my_add(1, 1) == 2
def test_my_add_floats():
assert my_add(.1, .2) == approx(.3)
Overwriting test_my_math.py
%%file my_math.py
def my_add(x, y):
return x - y
Overwriting my_math.py
!pytest -v test_my_math.py
============================= test session starts ==============================
platform linux -- Python 3.13.2, pytest-8.3.5, pluggy-1.5.0 -- /home/bb1000-vt25/miniconda3/envs/bb1000/bin/python3.13
cachedir: .pytest_cache
rootdir: /home/bb1000-vt25/bb1000
plugins: cov-6.0.0, anyio-4.8.0
collected 2 items
test_my_math.py::test_my_add FAILED [ 50%]
test_my_math.py::test_my_add_floats FAILED [100%]
=================================== FAILURES ===================================
_________________________________ test_my_add __________________________________
def test_my_add():
> assert my_add(1, 1) == 2
E assert 0 == 2
E + where 0 = my_add(1, 1)
test_my_math.py:5: AssertionError
______________________________ test_my_add_floats ______________________________
def test_my_add_floats():
> assert my_add(.1, .2) == approx(.3)
E assert -0.1 == 0.3 ± 3.0e-07
E
E comparison failed
E Obtained: -0.1
E Expected: 0.3 ± 3.0e-07
test_my_math.py:8: AssertionError
=========================== short test summary info ============================
FAILED test_my_math.py::test_my_add - assert 0 == 2
FAILED test_my_math.py::test_my_add_floats - assert -0.1 == 0.3 ± 3.0e-07
============================== 2 failed in 0.08s ===============================
%%file my_math.py
def my_add(x, y):
return x + y
Overwriting my_math.py
!pytest -v test_my_math.py
============================= test session starts ==============================
platform linux -- Python 3.13.2, pytest-8.3.5, pluggy-1.5.0 -- /home/bb1000-vt25/miniconda3/envs/bb1000/bin/python3.13
cachedir: .pytest_cache
rootdir: /home/bb1000-vt25/bb1000
plugins: cov-6.0.0, anyio-4.8.0
collected 2 items
test_my_math.py::test_my_add PASSED [ 50%]
test_my_math.py::test_my_add_floats PASSED [100%]
============================== 2 passed in 0.02s ===============================
%%file test_leap.py
from leap import is_leap_year
def test_leap_year():
assert is_leap_year(2000) == True
assert is_leap_year(1999) == False
assert is_leap_year(1998) == False
assert is_leap_year(1996) == True
assert is_leap_year(1900) == False
assert is_leap_year(1800) == False
assert is_leap_year(1600) == True
Overwriting test_leap.py
%%file leap.py
def is_leap_year(year):
"""
Returns True for leap years
"""
if year % 4 == 0:
return True
else:
return False
Overwriting leap.py
!pytest test_leap.py
============================= test session starts ==============================
platform linux -- Python 3.13.2, pytest-8.3.5, pluggy-1.5.0
rootdir: /home/bb1000-vt25/bb1000
plugins: cov-6.0.0, anyio-4.8.0
collected 1 item
test_leap.py F [100%]
=================================== FAILURES ===================================
________________________________ test_leap_year ________________________________
def test_leap_year():
assert is_leap_year(2000) == True
assert is_leap_year(1999) == False
assert is_leap_year(1998) == False
assert is_leap_year(1996) == True
> assert is_leap_year(1900) == False
E assert True == False
E + where True = is_leap_year(1900)
test_leap.py:7: AssertionError
=========================== short test summary info ============================
FAILED test_leap.py::test_leap_year - assert True == False
============================== 1 failed in 0.07s ===============================
%%file leap.py
def is_leap_year(year):
"""
Returns True for leap years
"""
if year % 100 == 0:
if year % 400 == 0:
return True
else:
return False
else:
if year % 4 == 0:
return True
else:
return False
Overwriting leap.py
!pytest -v test_leap.py
============================= test session starts ==============================
platform linux -- Python 3.13.2, pytest-8.3.5, pluggy-1.5.0 -- /home/bb1000-vt25/miniconda3/envs/bb1000/bin/python3.13
cachedir: .pytest_cache
rootdir: /home/bb1000-vt25/bb1000
plugins: cov-6.0.0, anyio-4.8.0
collected 1 item
test_leap.py::test_leap_year PASSED [100%]
============================== 1 passed in 0.02s ===============================
# cleanup / improve code
%%file leap.py
def is_leap_year(year):
"""
Returns True for leap years
"""
if year % 100 == 0:
return year % 400 == 0
else:
return year % 4 == 0
Overwriting leap.py
!pytest -v
============================= test session starts ==============================
platform linux -- Python 3.13.2, pytest-8.3.5, pluggy-1.5.0 -- /home/bb1000-vt25/miniconda3/envs/bb1000/bin/python3.13
cachedir: .pytest_cache
rootdir: /home/bb1000-vt25/bb1000
plugins: cov-6.0.0, anyio-4.8.0
collected 8 items
git_demo/test_savings.py::test_one_year PASSED [ 12%]
git_demo/test_savings.py::test_two_years PASSED [ 25%]
git_demo/test_savings.py::test_two_years_only_inital_deposit PASSED [ 37%]
test_leap.py::test_leap_year PASSED [ 50%]
test_my_math.py::test_my_add PASSED [ 62%]
test_my_math.py::test_my_add_floats PASSED [ 75%]
test_timestamps.py::test_1 PASSED [ 87%]
test_timestamps.py::test_6 FAILED [100%]
=================================== FAILURES ===================================
____________________________________ test_6 ____________________________________
def test_6():
"""
>>> sum_timestamps(['6:35:32', '2:45:48', '40:10'])
'10:01:30'
"""
> assert timestamps(['6:35:32', '2:45:48', '40:10']) == '10:01:30'
E TypeError: 'module' object is not callable
test_timestamps.py:13: TypeError
=========================== short test summary info ============================
FAILED test_timestamps.py::test_6 - TypeError: 'module' object is not callable
========================= 1 failed, 7 passed in 0.54s ==========================
%%file test_leap.py
from leap import is_leap_year
import pytest
TEST_DATA = [
(2000, True),
(1999, False),
(1998, False),
(1996, True),
(1900, False),
(1800, False),
(1600, True),
]
@pytest.mark.parametrize('year,expected', TEST_DATA)
def test_leap_year(year, expected):
assert is_leap_year(year) == expected
Overwriting test_leap.py
!pytest -v
============================= test session starts ==============================
platform linux -- Python 3.13.2, pytest-8.3.5, pluggy-1.5.0 -- /home/bb1000-vt25/miniconda3/envs/bb1000/bin/python3.13
cachedir: .pytest_cache
rootdir: /home/bb1000-vt25/bb1000
plugins: cov-6.0.0, anyio-4.8.0
collected 14 items
git_demo/test_savings.py::test_one_year PASSED [ 7%]
git_demo/test_savings.py::test_two_years PASSED [ 14%]
git_demo/test_savings.py::test_two_years_only_inital_deposit PASSED [ 21%]
test_leap.py::test_leap_year[2000-True] PASSED [ 28%]
test_leap.py::test_leap_year[1999-False] PASSED [ 35%]
test_leap.py::test_leap_year[1998-False] PASSED [ 42%]
test_leap.py::test_leap_year[1996-True] PASSED [ 50%]
test_leap.py::test_leap_year[1900-False] PASSED [ 57%]
test_leap.py::test_leap_year[1800-False] PASSED [ 64%]
test_leap.py::test_leap_year[1600-True] PASSED [ 71%]
test_my_math.py::test_my_add PASSED [ 78%]
test_my_math.py::test_my_add_floats PASSED [ 85%]
test_timestamps.py::test_1 PASSED [ 92%]
test_timestamps.py::test_6 FAILED [100%]
=================================== FAILURES ===================================
____________________________________ test_6 ____________________________________
def test_6():
"""
>>> sum_timestamps(['6:35:32', '2:45:48', '40:10'])
'10:01:30'
"""
> assert timestamps(['6:35:32', '2:45:48', '40:10']) == '10:01:30'
E TypeError: 'module' object is not callable
test_timestamps.py:13: TypeError
=========================== short test summary info ============================
FAILED test_timestamps.py::test_6 - TypeError: 'module' object is not callable
========================= 1 failed, 13 passed in 0.47s =========================
# coverage
!conda install pytest-cov -y
Channels:
- defaults
Platform: linux-64
Collecting package metadata (repodata.json): done
Solving environment: done
==> WARNING: A newer version of conda exists. <==
current version: 25.1.1
latest version: 25.3.1
Please update conda by running
$ conda update -n base -c defaults conda
# All requested packages already installed.
!pytest test_leap.py --cov leap
============================= test session starts ==============================
platform linux -- Python 3.13.2, pytest-8.3.5, pluggy-1.5.0
rootdir: /home/bb1000-vt25/bb1000
plugins: cov-6.0.0, anyio-4.8.0
collected 7 items
test_leap.py ....... [100%]
---------- coverage: platform linux, python 3.13.2-final-0 -----------
Name Stmts Miss Cover
-----------------------------
leap.py 4 0 100%
-----------------------------
TOTAL 4 0 100%
============================== 7 passed in 0.06s ===============================
!pytest test_leap.py --cov leap --cov-report=html
============================= test session starts ==============================
platform linux -- Python 3.13.2, pytest-8.3.5, pluggy-1.5.0
rootdir: /home/bb1000-vt25/bb1000
plugins: cov-6.0.0, anyio-4.8.0
collected 7 items
test_leap.py ....... [100%]
---------- coverage: platform linux, python 3.13.2-final-0 -----------
Coverage HTML written to dir htmlcov
============================== 7 passed in 0.09s ===============================
doctest#
%%file leap.py
def is_leap_year(year):
"""
Returns True for leap years
>>> is_leap_year(2000)
True
>>> is_leap_year(1900)
False
"""
if year % 100 == 0:
return year % 400 == 0
else:
return year % 4 == 0
Overwriting leap.py
!python -m doctest leap.py -v
Trying:
is_leap_year(2000)
Expecting:
True
ok
Trying:
is_leap_year(1900)
Expecting:
False
ok
1 item had no tests:
leap
1 item passed all tests:
2 tests in leap.is_leap_year
2 tests in 2 items.
2 passed.
Test passed.
# indentation error
if True:
print("Hello")
print("Hello")
Cell In[481], line 4
print("Hello")
^
IndentationError: unexpected indent
# indentation 2-spaces
if True:
print("Hello")
print("Hello")
Hello
Hello
# indentation 4-spaces (PEP8 convention)
if True:
print("Hello")
print("Hello")
Hello
Hello
Version control#
!git --help
usage: git [-v | --version] [-h | --help] [-C <path>] [-c <name>=<value>]
[--exec-path[=<path>]] [--html-path] [--man-path] [--info-path]
[-p | --paginate | -P | --no-pager] [--no-replace-objects] [--no-lazy-fetch]
[--no-optional-locks] [--no-advice] [--bare] [--git-dir=<path>]
[--work-tree=<path>] [--namespace=<name>] [--config-env=<name>=<envvar>]
<command> [<args>]
These are common Git commands used in various situations:
start a working area (see also: git help tutorial)
clone Clone a repository into a new directory
init Create an empty Git repository or reinitialize an existing one
work on the current change (see also: git help everyday)
add Add file contents to the index
mv Move or rename a file, a directory, or a symlink
restore Restore working tree files
rm Remove files from the working tree and from the index
examine the history and state (see also: git help revisions)
bisect Use binary search to find the commit that introduced a bug
diff Show changes between commits, commit and working tree, etc
grep Print lines matching a pattern
log Show commit logs
show Show various types of objects
status Show the working tree status
grow, mark and tweak your common history
branch List, create, or delete branches
commit Record changes to the repository
merge Join two or more development histories together
rebase Reapply commits on top of another base tip
reset Reset current HEAD to the specified state
switch Switch branches
tag Create, list, delete or verify a tag object signed with GPG
collaborate (see also: git help workflows)
fetch Download objects and refs from another repository
pull Fetch from and integrate with another repository or a local branch
push Update remote refs along with associated objects
'git help -a' and 'git help -g' list available subcommands and some
concept guides. See 'git help <command>' or 'git help <concept>'
to read about a specific subcommand or concept.
See 'git help git' for an overview of the system.
configuration#
!git config --global user.name "Olav Vahtras"
!git config --global user.email vahtras@kth.se
!more ~/.gitconfig
[user]
email = vahtras@kth.se
name = Olav Vahtras
%cd ~/bb1000
/home/bb1000-vt25/bb1000
%mkdir git_demo
%cd git_demo/
/home/bb1000-vt25/bb1000/git_demo
#initialize current folder for git
! git init .
hint: Using 'master' as the name for the initial branch. This default branch name
hint: is subject to change. To configure the initial branch name to use in all
hint: of your new repositories, which will suppress this warning, call:
hint:
hint: git config --global init.defaultBranch <name>
hint:
hint: Names commonly chosen instead of 'master' are 'main', 'trunk' and
hint: 'development'. The just-created branch can be renamed via this command:
hint:
hint: git branch -m <name>
Initialized empty Git repository in /home/bb1000-vt25/bb1000/git_demo/.git/
!ls -a
. .. .git
!git status
On branch master
No commits yet
nothing to commit (create/copy files and use "git add" to track)
# work...
%%file savings.py
# Calculate retirement savings
def savings_calculator(amount, interest):
final_amount = amount + amount*interest
return final_amount
Overwriting savings.py
%%file test_savings.py
import savings
def test_one_year():
initial_amount = 500
annual_interest = .05
expected_final = 525
calculated_final = savings.savings_calculator(initial_amount, annual_interest)
assert calculated_final == expected_final
Overwriting test_savings.py
!git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
__pycache__/
savings.py
test_savings.py
nothing added to commit but untracked files present (use "git add" to track)
# create .gitignore file to list files to ignore
%%file .gitignore
*.pyc
Writing .gitignore
!git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
.gitignore
savings.py
test_savings.py
nothing added to commit but untracked files present (use "git add" to track)
# save changes to the cache
!git add .
!git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: .gitignore
new file: savings.py
new file: test_savings.py
!git commit -m "Initial commit"
[master (root-commit) a324f3f] Initial commit
3 files changed, 14 insertions(+)
create mode 100644 .gitignore
create mode 100644 savings.py
create mode 100644 test_savings.py
!git status
On branch master
nothing to commit, working tree clean
!git log
commit a324f3f127df2eb866b3f870901ab0c91baf41ff (HEAD -> master)
Author: Olav Vahtras <vahtras@kth.se>
Date: Tue May 20 21:50:43 2025 +0200
Initial commit
# new changes to code
%%file savings.py
# Calculate retirement savings
def savings_calculator(amount, interest, years=1):
final_amount = amount*(1 + interest)**years
return final_amount
Overwriting savings.py
!git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: savings.py
no changes added to commit (use "git add" and/or "git commit -a")
# add all updated files to the cache
!git add -u
!git status
On branch master
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
modified: savings.py
#save changes to repository
!git commit -m 'Allow for several years of savings'
[master 0075416] Allow for several years of savings
1 file changed, 3 insertions(+), 3 deletions(-)
!git status
On branch master
nothing to commit, working tree clean
!git log
commit 0075416fafd7a9f5432bfb9bcd0b7461221215ce (HEAD -> master)
Author: Olav Vahtras <vahtras@kth.se>
Date: Tue May 20 21:55:23 2025 +0200
Allow for several years of savings
commit a324f3f127df2eb866b3f870901ab0c91baf41ff
Author: Olav Vahtras <vahtras@kth.se>
Date: Tue May 20 21:50:43 2025 +0200
Initial commit
!git log --oneline
0075416 (HEAD -> master) Allow for several years of savings
a324f3f Initial commit
# new changes
%%file savings.py
# Calculate retirement savings
def savings_calculator(amount, interest, years=1):
final_amount = 0
for year in range(years):
final_amount = (amount + final_amount)*(1 + interest)
return final_amount
Overwriting savings.py
!git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: savings.py
no changes added to commit (use "git add" and/or "git commit -a")
!git diff
diff --git a/savings.py b/savings.py
index 715f219..46443a6 100644
--- a/savings.py
+++ b/savings.py
@@ -1,5 +1,7 @@
# Calculate retirement savings
def savings_calculator(amount, interest, years=1):
- final_amount = amount*(1 + interest)**years
- return final_amount(bb1000) bb1000-vt25@bat:~/bb1000/git_demo_backup$
+ final_amount = 0
+ for year in range(years):
+ final_amount = (amount + final_amount)*(1 + interest)
+ return final_amount
!git add -u
!git status
On branch master
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
modified: savings.py
!git commit -m "Annual deposits with for loop"
[master ea52645] Annual deposits with for loop
1 file changed, 4 insertions(+), 2 deletions(-)
!git status
On branch master
nothing to commit, working tree clean
!git log
commit ea526456f52d4a6e361f46ec799a7748ea257469 (HEAD -> master)
Author: Olav Vahtras <vahtras@kth.se>
Date: Tue May 20 22:00:38 2025 +0200
Annual deposits with for loop
commit 0075416fafd7a9f5432bfb9bcd0b7461221215ce
Author: Olav Vahtras <vahtras@kth.se>
Date: Tue May 20 21:55:23 2025 +0200
Allow for several years of savings
commit a324f3f127df2eb866b3f870901ab0c91baf41ff
Author: Olav Vahtras <vahtras@kth.se>
Date: Tue May 20 21:50:43 2025 +0200
Initial commit
!git log --oneline
ea52645 (HEAD -> master) Annual deposits with for loop
0075416 Allow for several years of savings
a324f3f Initial commit
# have a look at the previous version
!git checkout 0075416
Note: switching to '0075416'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by switching back to a branch.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -c with the switch command. Example:
git switch -c <new-branch-name>
Or undo this operation with:
git switch -
Turn off this advice by setting config variable advice.detachedHead to false
HEAD is now at 0075416 Allow for several years of savings
!git log --oneline
0075416 (HEAD) Allow for several years of savings
a324f3f Initial commit
!git log --oneline --all
ea52645 (master) Annual deposits with for loop
0075416 (HEAD) Allow for several years of savings
a324f3f Initial commit
!git switch master
Previous HEAD position was 0075416 Allow for several years of savings
Switched to branch 'master'
!git log --oneline --all
ea52645 (HEAD -> master) Annual deposits with for loop
0075416 Allow for several years of savings
a324f3f Initial commit
Branches#
Two lines of development
a script that runs from the command line
variation of the years that I want to deposit
two git branches
!git branch script
!git branch varying-deposits
!git log --oneline
ea52645 (HEAD -> master, varying-deposits, script) Annual deposits with for loop
0075416 Allow for several years of savings
a324f3f Initial commit
!git switch script
Switched to branch 'script'
!git log --oneline
ea52645 (HEAD -> script, varying-deposits, master) Annual deposits with for loop
0075416 Allow for several years of savings
a324f3f Initial commit
%%file savings.py
# Calculate retirement savings
import sys
def savings_calculator(amount, interest, years=1):
final_amount = 0
for year in range(years):
final_amount = round((amount + final_amount)*(1 + interest), 2)
return final_amount
if __name__ == "__main__":
if len(sys.argv) == 3:
amount = int(sys.argv[1])
interest = float(sys.argv[2])
final = savings_calculator(amount, interest)
years = 1
elif len(sys.argv) == 4:
amount = int(sys.argv[1])
interest = float(sys.argv[2])
years = int(sys.argv[3])
final = savings_calculator(amount, interest, years)
else:
print(f"Usage: {sys.argv[0]} amount interest [years]")
exit()
print(f"Savings after {years} years: {final}")
Overwriting savings.py
!git add -u
!git commit -m "Include command-line arguments"
[script 65a3b2d] Include command-line arguments
1 file changed, 19 insertions(+), 1 deletion(-)
!git log --oneline --all
65a3b2d (HEAD -> script) Include command-line arguments
ea52645 (varying-deposits, master) Annual deposits with for loop
0075416 Allow for several years of savings
a324f3f Initial commit
!git switch varying-deposits
Switched to branch 'varying-deposits'
!git log --oneline --all
65a3b2d (script) Include command-line arguments
ea52645 (HEAD -> varying-deposits, master) Annual deposits with for loop
0075416 Allow for several years of savings
a324f3f Initial commit
# new changes related to years of depositing
%%file savings.py
# Calculate retirement savings
def savings_calculator(amount, interest, years=1, stop_deposit=None):
final_amount = 0
if stop_deposit is None:
stop_deposit = years
for year in range(years):
if year < stop_deposit:
final_amount = (amount + final_amount)*(1 + interest)
else:
final_amount = final_amount*(1 + interest)
return final_amount
Overwriting savings.py
!git diff
diff --git a/savings.py b/savings.py
index 46443a6..d1611da 100644
--- a/savings.py
+++ b/savings.py
@@ -1,7 +1,13 @@
# Calculate retirement savings
-def savings_calculator(amount, interest, years=1):
+def savings_calculator(amount, interest, years=1, stop_deposit=None):
final_amount = 0
+ if stop_deposit is None:
+ stop_deposit = years
+
for year in range(years):
- final_amount = (amount + final_amount)*(1 + interest)
+ if year < stop_deposit:
+ final_amount = (amount + final_amount)*(1 + interest)
+ else:
+ final_amount = final_amount*(1 + interest)
return final_amount
!git add -u
!git commit -m "Changes for optional deposit years"
[varying-deposits 335928a] Changes for optional deposit years
1 file changed, 8 insertions(+), 2 deletions(-)
!git log --oneline --all
335928a (HEAD -> varying-deposits) Changes for optional deposit years
65a3b2d (script) Include command-line arguments
ea52645 (master) Annual deposits with for loop
0075416 Allow for several years of savings
a324f3f Initial commit
# include changes in script to master
!git switch master
Switched to branch 'master'
!git merge script
Updating ea52645..65a3b2d
Fast-forward
savings.py | 20 +++++++++++++++++++-
1 file changed, 19 insertions(+), 1 deletion(-)
!git log --oneline --all
335928a (varying-deposits) Changes for optional deposit years
65a3b2d (HEAD -> master, script) Include command-line arguments
ea52645 Annual deposits with for loop
0075416 Allow for several years of savings
a324f3f Initial commit
!git merge varying-deposits
Auto-merging savings.py
CONFLICT (content): Merge conflict in savings.py
Automatic merge failed; fix conflicts and then commit the result.
!git status
On branch master
You have unmerged paths.
(fix conflicts and run "git commit")
(use "git merge --abort" to abort the merge)
Unmerged paths:
(use "git add <file>..." to mark resolution)
both modified: savings.py
no changes added to commit (use "git add" and/or "git commit -a")
The file savings.py in a state of conflict:
# Calculate retirement savings
import sys
def savings_calculator(amount, interest, years=1, stop_deposit=None):
final_amount = 0
if stop_deposit is None:
stop_deposit = years
for year in range(years):
<<<<<<< HEAD
final_amount = round((amount + final_amount)*(1 + interest), 2)
return final_amount
if __name__ == "__main__":
if len(sys.argv) == 3:
amount = int(sys.argv[1])
interest = float(sys.argv[2])
final = savings_calculator(amount, interest)
years = 1
elif len(sys.argv) == 4:
amount = int(sys.argv[1])
interest = float(sys.argv[2])
years = int(sys.argv[3])
final = savings_calculator(amount, interest, years)
else:
print(f"Usage: {sys.argv[0]} amount interest [years]")
exit()
print(f"Savings after {years} years: {final}")
=======
if year < stop_deposit:
final_amount = (amount + final_amount)*(1 + interest)
else:
final_amount = final_amount*(1 + interest)
return final_amount
>>>>>>> varying-deposits
fix merge
%%file savings.py
# Calculate retirement savings
import sys
def savings_calculator(amount, interest, years=1, stop_deposit=None):
final_amount = 0
if stop_deposit is None:
stop_deposit = years
for year in range(years):
if year < stop_deposit:
final_amount = (amount + final_amount)*(1 + interest)
else:
final_amount = final_amount*(1 + interest)
return final_amount
if __name__ == "__main__":
if len(sys.argv) == 3:
amount = int(sys.argv[1])
interest = float(sys.argv[2])
final = savings_calculator(amount, interest)
years = 1
elif len(sys.argv) == 4:
amount = int(sys.argv[1])
interest = float(sys.argv[2])
years = int(sys.argv[3])
final = savings_calculator(amount, interest, years)
else:
print(f"Usage: {sys.argv[0]} amount interest [years]")
exit()
print(f"Savings after {years} years: {final}")
Overwriting savings.py
!git status
On branch master
You have unmerged paths.
(fix conflicts and run "git commit")
(use "git merge --abort" to abort the merge)
Unmerged paths:
(use "git add <file>..." to mark resolution)
both modified: savings.py
no changes added to commit (use "git add" and/or "git commit -a")
%%file savings.py
# Calculate retirement savings
import sys
def savings_calculator(amount, interest, years=1, stop_deposit=None):
final_amount = 0
if stop_deposit is None:
stop_deposit = years
for year in range(years):
if year < stop_deposit:
final_amount = (amount + final_amount)*(1 + interest)
else:
final_amount = final_amount*(1 + interest)
return final_amount
if __name__ == "__main__":
if len(sys.argv) == 3:
amount = int(sys.argv[1])
interest = float(sys.argv[2])
final = savings_calculator(amount, interest)
years = 1
elif len(sys.argv) == 4:
amount = int(sys.argv[1])
interest = float(sys.argv[2])
years = int(sys.argv[3])
final = savings_calculator(amount, interest, years)
else:
print(f"Usage: {sys.argv[0]} amount interest [years]")
exit()
print(f"Savings after {years} years: {final}")
Overwriting savings.py
!git add -u
!git commit -m "fix conflicts"
[master a71a30b] fix conflicts
!git status
On branch master
nothing to commit, working tree clean
Remote repositories#
!git remote add kth-github git@gits-15.sys.kth.se:BB1000/git_demo.git
!git remote
kth-github
!git remote -v
kth-github git@gits-15.sys.kth.se:BB1000/git_demo.git (fetch)
kth-github git@gits-15.sys.kth.se:BB1000/git_demo.git (push)
!git push kth-github master
Enumerating objects: 20, done.
Counting objects: 100% (20/20), done.
Delta compression using up to 12 threads
Compressing objects: 100% (19/19), done.
Writing objects: 100% (20/20), 2.50 KiB | 2.50 MiB/s, done.
Total 20 (delta 3), reused 0 (delta 0), pack-reused 0 (from 0)
remote: Resolving deltas: 100% (3/3), done.
To gits-15.sys.kth.se:BB1000/git_demo.git
+ 56b59e6...a71a30b master -> master (forced update)
Enumerating objects: 23, done.
Counting objects: 100% (23/23), done.
Delta compression using up to 12 threads
Compressing objects: 100% (22/22), done.
Writing objects: 100% (23/23), 2.66 KiB | 680.00 KiB/s, done.
Total 23 (delta 6), reused 0 (delta 0), pack-reused 0 (from 0)
remote: Resolving deltas: 100% (6/6), done.
To gits-15.sys.kth.se:BB1000/git_demo.git
* [new branch] master -> master
!git log --oneline --all
a71a30b (HEAD -> master, kth-github/master) fix conflicts
335928a (varying-deposits) Changes for optional deposit years
65a3b2d (script) Include command-line arguments
ea52645 Annual deposits with for loop
0075416 Allow for several years of savings
a324f3f Initial commit
%cd /tmp
!git clone git@gits-15.sys.kth.se:BB1000/git_demo
Cloning into 'git_demo'...
remote: Enumerating objects: 23, done.
remote: Counting objects: 100% (23/23), done.
remote: Compressing objects: 100% (16/16), done.
remote: Total 23 (delta 6), reused 23 (delta 6), pack-reused 0
Receiving objects: 100% (23/23), done.
Resolving deltas: 100% (6/6), done.
%cd git_demo
/tmp/git_demo
!git log --oneline --all
5ee6af4 (HEAD -> master, origin/master, origin/HEAD) fix conflicts
25bbab9 Changes for optional deposit years
a884958 Include command-line arguments
542ba6f Annual deposits with for loop
9eb01ff Allow for several years of savings
700da30 Initial commit
%cd /tmp/git_demo
/tmp/git_demo
# on second computer/ second user
!git log --oneline --all
85ebcbf (HEAD -> master) Define start end stop deposit years
5ee6af4 (origin/master, origin/HEAD) fix conflicts
25bbab9 Changes for optional deposit years
a884958 Include command-line arguments
542ba6f Annual deposits with for loop
9eb01ff Allow for several years of savings
700da30 Initial commit
!git remote -v
origin git@gits-15.sys.kth.se:BB1000/git_demo (fetch)
origin git@gits-15.sys.kth.se:BB1000/git_demo (push)
!git push origin master
Enumerating objects: 5, done.
Counting objects: 100% (5/5), done.
Delta compression using up to 12 threads
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 400 bytes | 400.00 KiB/s, done.
Total 3 (delta 1), reused 0 (delta 0), pack-reused 0 (from 0)
remote: Resolving deltas: 100% (1/1), completed with 1 local object.
To gits-15.sys.kth.se:BB1000/git_demo
5ee6af4..85ebcbf master -> master
# back to first computer
%cd ~/bb1000/git_demo
/home/bb1000-vt25/bb1000/git_demo
#update local information
# two possibilities: git pull/ git fetch and git merge
!git remote -v
kth-github git@gits-15.sys.kth.se:BB1000/git_demo.git (fetch)
kth-github git@gits-15.sys.kth.se:BB1000/git_demo.git (push)
!git log --oneline --all
5ee6af4 (HEAD -> master, kth-github/master) fix conflicts
25bbab9 (varying-deposits) Changes for optional deposit years
a884958 (script) Include command-line arguments
542ba6f Annual deposits with for loop
9eb01ff Allow for several years of savings
700da30 Initial commit
!git fetch --all # update our local information about all remote
remote: Enumerating objects: 5, done.
remote: Counting objects: 100% (5/5), done.
remote: Compressing objects: 100% (2/2), done.
remote: Total 3 (delta 1), reused 3 (delta 1), pack-reused 0
Unpacking objects: 100% (3/3), 380 bytes | 380.00 KiB/s, done.
From gits-15.sys.kth.se:BB1000/git_demo
5ee6af4..85ebcbf master -> kth-github/master
!git log --oneline --all
85ebcbf (kth-github/master, kth-github/HEAD) Define start end stop deposit years
5ee6af4 (HEAD -> master) fix conflicts
25bbab9 (varying-deposits) Changes for optional deposit years
a884958 (script) Include command-line arguments
542ba6f Annual deposits with for loop
9eb01ff Allow for several years of savings
700da30 Initial commit
!git merge kth-github/master
Updating 5ee6af4..85ebcbf
Fast-forward
savings.py | 7 +++++--
1 file changed, 5 insertions(+), 2 deletions(-)
!git log --oneline --all
85ebcbf (HEAD -> master, kth-github/master, kth-github/HEAD) Define start end stop deposit years
5ee6af4 fix conflicts
25bbab9 (varying-deposits) Changes for optional deposit years
a884958 (script) Include command-line arguments
542ba6f Annual deposits with for loop
9eb01ff Allow for several years of savings
700da30 Initial commit
# include new updates with git pull
!git pull
remote: Enumerating objects: 5, done.
remote: Counting objects: 100% (5/5), done.
remote: Compressing objects: 100% (3/3), done.
remote: Total 3 (delta 1), reused 0 (delta 0), pack-reused 0
Unpacking objects: 100% (3/3), 395 bytes | 395.00 KiB/s, done.
From gits-15.sys.kth.se:BB1000/git_demo
85ebcbf..cbce447 master -> kth-github/master
There is no tracking information for the current branch.
Please specify which branch you want to merge with.
See git-pull(1) for details.
git pull <remote> <branch>
If you wish to set tracking information for this branch you can do so with:
git branch --set-upstream-to=kth-github/<branch> master
!git pull kth-github master
From gits-15.sys.kth.se:BB1000/git_demo
* branch master -> FETCH_HEAD
Updating 85ebcbf..cbce447
Fast-forward
savings.py | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
!git log --oneline --all
cbce447 (HEAD -> master, kth-github/master, kth-github/HEAD) Update savings.py: round output to two decimals
85ebcbf Define start end stop deposit years
5ee6af4 fix conflicts
25bbab9 (varying-deposits) Changes for optional deposit years
a884958 (script) Include command-line arguments
542ba6f Annual deposits with for loop
9eb01ff Allow for several years of savings
700da30 Initial commit
update: plot savings history#
# %load git_demo/savings.py
# Calculate retirement savings
import sys
import matplotlib.pyplot as plt
def savings_calculator(amount, interest, years=1, start_deposit=None, stop_deposit=None, plot=False):
final_amount = 0
savings_by_year = []
if start_deposit is None:
start_deposit = 0
if stop_deposit is None:
stop_deposit = years
for year in range(years):
if start_deposit <= year < stop_deposit:
final_amount = (amount + final_amount)*(1 + interest)
else:
final_amount = final_amount*(1 + interest)
final_amount = round(final_amount, 2)
#print(year, final_amount)
savings_by_year.append(final_amount)
if plot:
plt.plot(savings_by_year)
return final_amount
Compare early career savings vs late career savings (10000 per year)
final = savings_calculator(10000, .1, years=40, start_deposit=0, stop_deposit=10, plot=True); print("Total deposits", 10000*10, ", final savings", final)
final = savings_calculator(10000, .1, years=40, start_deposit=10, stop_deposit=40, plot=True); print("Total deposits", 10000*30, ", final savings", final)
plt.show()
Total deposits 100000 , final savings 3059084.15
Total deposits 300000 , final savings 1809434.33
Conclusion: the late saver who puts down more money never catches up to the early saver, due to compound intererst over several years
Advanced topics#
Decorators#
# function with arbitrary arguments
#example
print('Hello')
print('Hello', 'world')
Hello
Hello world
def f(*args):
print(args)
f()
()
f('Hello')
('Hello',)
f('Hello', 'world')
('Hello', 'world')
def g(*args, **kwargs):
print('In function g:')
print(args)
print(kwargs)
g()
In function g:
()
{}
g('Hello', who='World')
In function g:
('Hello',)
{'who': 'World'}
def h(*args, **kwargs):
print('in function h:', args, kwargs)
g(*args, **kwargs)
h('Hello', who='World')
in function h: ('Hello',) {'who': 'World'}
In function g:
('Hello',)
{'who': 'World'}
# example timing
import math
import time
def slow_math(x):
time.sleep(1)
return math.sqrt(x)
t1 = time.time()
slow_math(2)
t2 = time.time()
print("Time used in slow_math", round(t2-t1, 1))
Time used in slow_math 1.0
t1 = time.time()
slow_math(3)
t2 = time.time()
print("Time used in slow_math", round(t2-t1, 1))
Time used in slow_math 1.0
# with a decorator - function that takes a function as input, and returns a function
def timeme(function):
def timed_function(*args, **kwargs):
t1 = time.time()
return_value = function(*args, **kwargs)
t2 = time.time()
print("Time used", round(t2-t1, 1))
return return_value
return timed_function
timeme(slow_math)
<function __main__.timeme.<locals>.timed_function(*args, **kwargs)>
slow_math_timed = timeme(slow_math)
slow_math_timed(4)
Time used 1.0
2.0
# decorator notation
@timeme # equivalent to slow_math=timeme(slow_math), redefinition
def slow_math(x):
time.sleep(1)
return math.sqrt(x)
slow_math(2)
Time used 1.0
1.4142135623730951
def debug(function):
def wrapped(*args, **kwargs):
print(function.__name__, 'called with', args, kwargs)
return_value = function(*args, **kwargs)
print(function.__name__, 'returns', return_value)
return return_value
return wrapped
@debug
def slow_math(x):
time.sleep(1)
return math.sqrt(x)
slow_math(2)
slow_math called with (2,) {}
slow_math returns 1.4142135623730951
1.4142135623730951
# combination of decorators
@timeme
@debug
def slow_math(x):
time.sleep(1)
return math.sqrt(x)
slow_math(2)
slow_math called with (2,) {}
slow_math returns 1.4142135623730951
Time used 1.0
1.4142135623730951
# combination of decorators
@debug
@timeme
def slow_math(x):
time.sleep(1)
return math.sqrt(x)
slow_math(2)
timed_function called with (2,) {}
Time used 1.0
timed_function returns 1.4142135623730951
1.4142135623730951
# combinatin of decorators with wraps
from functools import wraps
def timeme(function):
@wraps(function)
def timed_function(*args, **kwargs):
t1 = time.time()
return_value = function(*args, **kwargs)
t2 = time.time()
print("Time used in", function.__name__, round(t2-t1, 1))
return return_value
return timed_function
def debug(function):
@wraps(function)
def wrapped(*args, **kwargs):
print(function.__name__, 'called with', args, kwargs)
return_value = function(*args, **kwargs)
print(function.__name__, 'returns', return_value)
return return_value
return wrapped
# combinatin of decorators with wraps
@timeme
@debug
def slow_math(x):
time.sleep(1)
return math.sqrt(x)
slow_math(2)
slow_math called with (2,) {}
slow_math returns 1.4142135623730951
Time used in slow_math 1.0
1.4142135623730951
## Context managers
#t1 = time.time()
#slow_math(2)
#t2 = time.time()
#print("Time used in slow_math", round(t2-t1, 1))
#example: opening files
with open('sample.txt', 'w') as f:
f.write('hello')
class TimeMe:
def __enter__(self):
self.t1 = time.time()
def __exit__(self, *args):
self.t2 = time.time()
print("Time used in block", round(self.t2 - self.t1, 1))
with TimeMe():
time.sleep(2)
Time used in block 2.0
Iterators#
li = ['hello', 'there', 'world']
# primitve iteration
for index in range(len(li)):
print(index)
print(li[index])
0
hello
1
there
2
world
# pythonic iteration
for member in li:
print(member)
hello
there
world
for member in enumerate(li):
print(member)
(0, 'hello')
(1, 'there')
(2, 'world')
for member in enumerate(li, start=1):
print(member)
(1, 'hello')
(2, 'there')
(3, 'world')
#dictionaries
dictionary = {'a':1, 'b':2}
for k in dictionary:
print(k, dictionary[k])
a 1
b 2
for k in dictionary.items():
print(k)
('a', 1)
('b', 2)
# internall in the for loop
dir(dictionary)
['__class__',
'__class_getitem__',
'__contains__',
'__delattr__',
'__delitem__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__getattribute__',
'__getitem__',
'__getstate__',
'__gt__',
'__hash__',
'__init__',
'__init_subclass__',
'__ior__',
'__iter__',
'__le__',
'__len__',
'__lt__',
'__ne__',
'__new__',
'__or__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__reversed__',
'__ror__',
'__setattr__',
'__setitem__',
'__sizeof__',
'__str__',
'__subclasshook__',
'clear',
'copy',
'fromkeys',
'get',
'items',
'keys',
'pop',
'popitem',
'setdefault',
'update',
'values']
dictionary.__iter__()
<dict_keyiterator at 0x7a37888ef650>
dir(dictionary.__iter__())
['__class__',
'__delattr__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__getattribute__',
'__getstate__',
'__gt__',
'__hash__',
'__init__',
'__init_subclass__',
'__iter__',
'__le__',
'__length_hint__',
'__lt__',
'__ne__',
'__new__',
'__next__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__setattr__',
'__sizeof__',
'__str__',
'__subclasshook__']
dictionary.__iter__().__next__() # get the first value in the sequence
'a'
dictionary_iterator = dictionary.__iter__() # same as iter(dictionary)
next(dictionary_iterator)
'a'
next(dictionary_iterator)
'b'
next(dictionary_iterator)
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
Cell In[168], line 1
----> 1 next(dictionary_iterator)
StopIteration:
# internally what happens during
for k in dictionary:
print(k)
a
b
Generators#
def myfunction(n):
i = 0
return i
myfunction(3)
0
def myrange(n):
i = 0
while i < n:
yield i
i += 1
myrange(3)
<generator object myrange at 0x7a37888f9cc0>
for element in myrange(3):
print(element)
0
1
2
# internally
myrange_iterator = myrange(3)
next(myrange_iterator)
0
next(myrange_iterator)
1
next(myrange_iterator)
2
next(myrange_iterator)
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
Cell In[190], line 1
----> 1 next(myrange_iterator)
StopIteration:
#Example: list the first n Fibonacci numbers: 0 1 1 2 3 5 8...
def fib(n):
counter = 0
a = 0
b = 1
while counter < n:
yield a
# b -> a
# a + b -> b
a, b = b, a + b
counter += 1
for fibnum in fib(5):
print(fibnum)
0
1
1
2
3
list(fib(20))
[0,
1,
1,
2,
3,
5,
8,
13,
21,
34,
55,
89,
144,
233,
377,
610,
987,
1597,
2584,
4181]
# Example: search lines in a file for something
%%file data.txt
hello c++
hello fortran
hello python
Writing data.txt
!grep python data.txt
hello python
def grep(search_string, filename):
with open(filename) as f:
for line in f:
if search_string in line:
yield line.strip('\n')
for matching_line in grep('hello', 'data.txt'):
print(matching_line)
hello c++
hello fortran
hello python
# Example: tail
!tail -f data.txt
hello c++
hello fortran
hello python
hello lisp
^C
def tail(filename):
with open(filename) as f:
while True:
line = f.readline()
if not line:
time.sleep(1)
continue
yield line
for line in tail('data.txt'):
print(line)
hello c++
hello fortran
hello python
hello lisp
hello rust
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
Cell In[207], line 1
----> 1 for line in tail('data.txt'):
2 print(line)
Cell In[206], line 6, in tail(filename)
4 line = f.readline()
5 if not line:
----> 6 time.sleep(1)
7 continue
8 yield line
KeyboardInterrupt:
# a more general way
f = open('data.txt')
def grep(search_string, f):
for line in f:
if search_string in line:
yield line.strip('\n')
for matching_line in grep('hello', f):
print(matching_line)
hello c++
hello fortran
hello python
hello lisp
hello rust
def tail(f):
while True:
line = f.readline()
if not line:
time.sleep(1)
continue
yield line
f = open('data.txt')
for line in tail(f):
print(line)
hello c++
hello fortran
hello python
hello lisp
hello rust
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
Cell In[212], line 2
1 f = open('data.txt')
----> 2 for line in tail(f):
3 print(line)
Cell In[210], line 5, in tail(f)
3 line = f.readline()
4 if not line:
----> 5 time.sleep(1)
6 continue
7 yield line
KeyboardInterrupt:
for line in grep('python', tail(open('data.txt'))):
print(line)
hello python
python for all
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
Cell In[215], line 1
----> 1 for line in grep('python', tail(open('data.txt'))):
2 print(line)
Cell In[208], line 5, in grep(search_string, f)
4 def grep(search_string, f):
----> 5 for line in f:
6 if search_string in line:
7 yield line.strip('\n')
Cell In[210], line 5, in tail(f)
3 line = f.readline()
4 if not line:
----> 5 time.sleep(1)
6 continue
7 yield line
KeyboardInterrupt:
Exceptions#
1/0
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
Cell In[2], line 1
----> 1 1/0
ZeroDivisionError: division by zero
try:
1 / 0
except ZeroDivisionError:
print("Warning: tried division by zero")
print("Continuing..")
Warning: tried division by zero
Continuing..